Estrategias de búsqueda en internet
Principios básicos sobre arquitectura, funcionamiento y uso de los motores de búsqueda
- Créditos
- 1. Los sistemas de recuperación de información
- 1.1. Los sistemas de recuperación de información
- 1.2. Los sistemas de recuperación en internet
- 1.3. Metadatos
- 1.4. El web semántico
- 2. Los motores de búsqueda: funcionamiento
- 2.1. Captura de información
- 2.2. Procesamiento y recuperación de información
- 2.3. Presentación de resultados
- 3. Los principios básicos de recuperación de información
- 4. Motores generalistas: Google y DuckDuckGo
- 5. Información académica y técnica: Google Académico
- 6. Producción científica en español: Dialnet
- 7. Normativa LOMLOE y MRCDD relacionada
Créditos
Jesús Tramullas Saz
Seminario Permanente en Información y Documentación Grado en Información y Documentación, Universidad de Zaragoza |
Versión 1.0. Octubre de 2022
Cualquier observación o detección de error en soporte.catedu.es
Los contenidos se distribuyen bajo licencia Creative Commons tipo BY-NC-SA excepto en los párrafos que se indique lo contrario.



Financiado por el Ministerio de Educación y Formación Profesional y por la Unión Europea - NextGenerationEU
![]()
1. Los sistemas de recuperación de información
Se exponen los fundamentos de los sistemas de recuperación de información y su desarrollo para internet. Se delinean las nociones básicas de metadatos y del web semántico.
1.1. Los sistemas de recuperación de información
El tratamiento y recuperación de la información ha sido una preocupación, y una actividad, que han llevado a cabo todas las sociedades. Desde una perspectiva académica, los fundamentos de esta disciplina se establecen progresivamente desde mediados del siglo XIX, cuando se establecen y se formalizan las enseñanzas superiores sobre bibliotecas, archivos y museos. Sin embargo, es necesario esperar hasta mediados del siglo XX para que se conforme la denominada Information Science, que traslada el centro de la actividad científica y profesional hacia diferentes sistemas de tratamiento y recuperación de información, mediados tecnológicamente, y cuyo objetivo final es satisfacer las necesidades de información de los usuarios.
La multiplicación del volumen de información científica y técnica, derivada del esfuerzo de la Segunda Guerra Mundial, trajo como consecuencia la necesidad de introducir máquinas que facilitasen el tratamiento, almacenamiento y recuperación de la información. El desarrollo del sistema SMART (System for the Mechanical Analysis and Retrieval of Text) por el equipo de G. Salton en la Cornell University, en la década de 1960, estableció los fundamentos de los modernos sistemas de recuperación de información, de los que los motores de búsqueda en internet son herederos. Las décadas entre 1970 y 1990 vieron un desarrollo progresivo de este tipo de sistemas de recuperación, así como la aparición de sistemas comerciales de pago, accesibles a través de redes de comunicaciones, que ofrecían principalmente acceso a bases de datos documentales de contenido científico, económico o financiero. Cuando se populariza el acceso a internet, a mediados de la década de 1990, ya existía un mercado previo y grupos de usuarios especializados en la búsqueda de información. Los motores de búsqueda en internet de la primera generación (AltaVista, Lycos…) pusieron al alcance de cualquier usuario capacidades hasta entonces limitadas a entornos cerrados y especializados. La aparición de Google en 1998 supuso la disponibilidad de una herramienta de fácil comprensión y uso para que cualquier usuario pudiese buscar y localizar información en internet.
Los sistemas de recuperación de información son aquellos que ofrecen al usuario funcionalidades para acceder a fuentes y recursos de información en entornos digitales, y consultar, recuperar y extraer de los mismos aquellos documentos cuyo contenido sea capaz de dar respuesta una cuestión planteada por el usuario. En muchas ocasiones, estos sistemas se presentan integrados en otros, por ejemplo como componentes de sistemas de gestión de documentos o sistemas de gestión de contenidos.
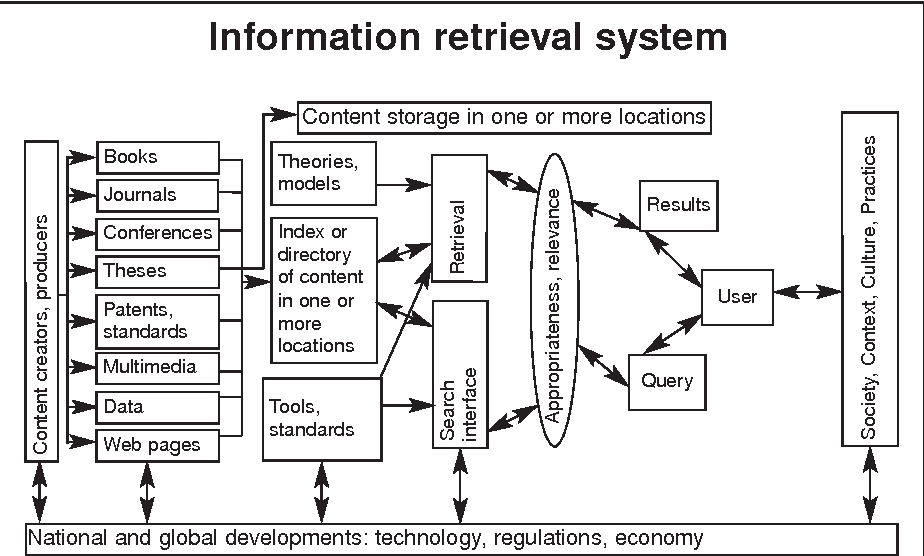 Fig. 1. Arquitectura de un sistema de recuperación de información (fuente original)
Fig. 1. Arquitectura de un sistema de recuperación de información (fuente original)
El factor clave que identifica a estos sistemas es su capacidad para procesar información textual, tanto en lo que se refiere a su adquisición y tratamiento, como en lo que respecta a la recuperación de la información contenida en el mismo. Esta información textual se recoge en documentos, que no suelen tener una estructura claramente formalizada (a diferencia de una hoja de cálculo o una tabla de base de datos, por ejemplo), y que pueden ofrecer múltiples combinaciones de contenido. La estructura funcional de un sistema de recuperación de información responde a:
- Captura de información: funcionalidades para capturar y almacenar documentos en diferentes formatos, para formar un corpus documental.
- Procesamiento de información: funcionalidades y algoritmos para generar representaciones de los documentos originales, según diferentes aproximaciones y criterios.
- Recuperación de información: funcionalidades y prestaciones para la formulación de expresiones o ecuaciones de búsqueda complejas, con una sintaxis propia y definida, y para la ejecución de esas expresiones contra el conjunto de representaciones resultado del procesamiento previo.
- Salida de información: las funcionalidades de presentación de resultados y de manipulación (filtrado, etc.), que se ofrecen al usuario con los resultados obtenidos de la ejecución de las expresiones de búsqueda.
Financiado por el Ministerio de Educación y Formación Profesional y por la Unión Europea - NextGenerationEU
![]()
1.2. Los sistemas de recuperación en internet
Las bases del éxito en la búsqueda y recuperación de información en internet son el conocimiento de los principios básicos de la recuperación de información y de los sistemas que la hacen posible, y de las características propias de los documentos existentes en internet. Las herramientas de búsqueda en internet aplican los principios sobre tratamiento y recuperación de información textual que se han revisado en el apartado anterior, y los usuarios disponen de similares prestaciones para la recuperación, y para su consulta y filtrado. Por lo tanto, resulta crucial que el usuario conozca los tipos de información, la variabilidad de formatos y las diferentes presentaciones que puede adoptar la información en internet. Ello le dotará de una mayor capacidad para conocer y valorar los resultados obtenidos durante el proceso de búsqueda.
Si bien un sistema de recuperación, en su formulación clásica, trabajaba sobre corpus documentales bastante homogéneos, no puede decirse lo mismo de los sistemas de recuperación en internet. Al tratarse de un entorno abierto y cambiante, las herramientas de búsqueda ofrecen listados de resultados, que dirigen al usuario hacia el documento original. Los cambios que se producen, por la propia dinámica del web, hacen que en ocasiones esa redirección no ofrezca los resultados esperados, y que haya que completar la búsqueda mediante procesos de exploración basados en la navegación. El usuario siempre debe pensar que no es suficiente, en recuperación de información en internet, con seguir los resultados obtenidos de un motor de búsqueda: hay que explorarlos, analizarlos, valorarlos, y seleccionarlos como adecuados, o desecharlos como no pertinentes. Los sistemas de recuperación de información en el web son un medio más, una fase intermedia, no un fin.
Una cuestión que debe tenerse en cuenta cuando se busca información en internet es que, contra la extendida creencia, no todo está disponible a través de los motores de búsqueda, ni en Wikipedia. La puesta en línea a través de internet,desde la década de 2000, de un gran número de fuentes y recursos de información, no supuso que su contenido fuese automáticamente incorporado al contenido procesado por los motores de búsqueda. Diferentes intereses comerciales y/o limitaciones técnicas excluyen enormes volúmenes de información de la vigilancia de los motores, configurando lo que se ha dado en llamar la “internet invisible”.
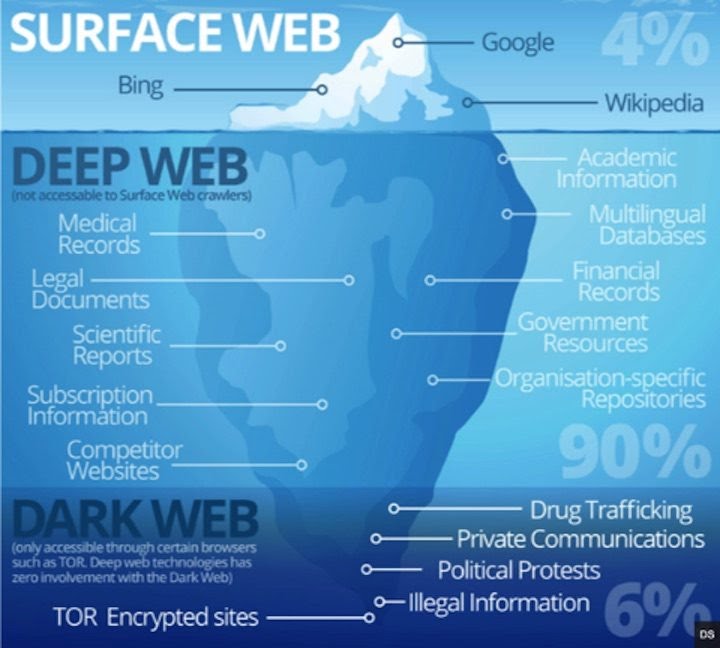 Fig. 2. El clásico iceberg de internet (múltiples fuentes)
Fig. 2. El clásico iceberg de internet (múltiples fuentes)
En realidad, estos contenidos no son invisibles para el usuario: lo son para los motores. La noción de internet invisible se asocia a la presencia en la red de recursos de información, cuyo contenido sólo está disponible a través de los sistemas de recuperación que ofrecen los propios recursos. Esto es debido precisamente a que, a su vez, esta internet invisible se encuentra recogida en bases de datos que sólo muestran su contenido cuando son interrogadas, generando páginas web dinámicas, que evidentemente no pueden ser descubiertas y analizadas por los robots que utilizan los buscadores tradicionales. Dentro de la esta área invisible se engloban los directorios y las bases de datos especializadas, los catálogos de bibliotecas, archivos y museos, las bases de datos de prensa, etc. La conclusión lógica que se deriva de ello es que el usuario debería conocer aquellos recursos de información especializada que resulten más adecuados para sus necesidades. Una aproximación común es comenzar la búsqueda en un motor generalista, para completarla en recursos especializados en una segunda fase.
Material complementario
Financiado por el Ministerio de Educación y Formación Profesional y por la Unión Europea - NextGenerationEU
![]()
1.3. Metadatos
Los metadatos han sido definidos ampliamente como “datos que describen otros datos” o “datos sobre los datos”. En el contexto de los procesos de búsqueda en internet, el término se utiliza para hacer referencia a conjuntos de datos etiquetados, incorporados al código de las páginas web, o a la cabecera de diferentes formatos de documentos, que incluyen información sobre autoría, título, fechas de relevancia, contenidos, descripción y otros elementos similares. Aunque es creciente el número de páginas web que van incorporando conjuntos de metadatos, en un gran volumen de contenido de internet no se han producido ni publicado estos metadatos. La descripción más precisa de los contenidos usando metadatos se lleva a cabo en el proceso de edición y publicación de contenidos, por parte de los creadores de los mismos. Esto explica que los sistemas de gestión de contenidos hayan ido incorporando funcionalidades de este tipo. Al igual que en el caso de la web semántica, los metadatos son para máquinas.
El esquema de metadatos más conocido es Dublin Core, un conjunto de quince elementos que están diseñados para describir cualquier tipo de información digital. Por su sencillez, se ha convertido en el esquema de referencia y en el formato de intercambio de infomación entre un buen número de servicios y productos de información digital.
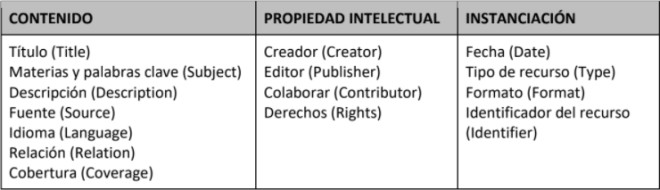 Fig. 3. Los 15 elementos del estándar Dublin Core (fuente original)
Fig. 3. Los 15 elementos del estándar Dublin Core (fuente original)
Los motores de búsqueda están preparados para identificar los conjuntos de metadatos, y para darles más importancia cuando proceden a generar la representación de una página web en sus índices. Evidentemente, esto supone que, a igualdad de contenido, una página con metadatos será mejor considerada por un motor para ofrecerla como respuesta a los usuarios, que la que no los lleve. Como puede imaginarse, esto tiene amplias repercusiones. La más conocida de ellas ha sido la aparición de técnicas de posicionamiento de resultados, o de optimización para motores de búsqueda (en inglés conocidas con el acrónimo SEO), merced a las cuales se intenta asegurar una posición mejor en los listados de respuestas de los motores de búsqueda. A la hora de analizar los metadatos, hay que tener en cuenta que también son ampliamente usados como herramienta de marketing en internet, por lo que en ocasiones puede suceder que un resultado, al ser evaluado, pueda resultar decepcionante. Los motores aprovechan los metadatos que encuentran, pero no pueden evaluar su validez.
Financiado por el Ministerio de Educación y Formación Profesional y por la Unión Europea - NextGenerationEU
![]()
1.4. El web semántico
A comienzos del siglo XXI Tim Berners-Lee y otros investigadores propusieron avanzar en la organización y recuperación de la información en el web adoptando un conjunto de métodos y técnicas que se englobaron bajo la expresión “web semántico”. En realidad, este esfuerzo está dirigido a estructurar contenidos de todo tipo de recursos y documentos web de acuerdo a un conjunto de estándares. La idea básica es incorporar datos etiquetados que sirvan para describir el contenido, el significado y la relación entre los diferentes elementos etiquetados.
Los usuarios de estos datos estructurados no son los usuarios finales: los destinatarios son las máquinas. El web semántico está diseñado para que sean las máquinas, mediante procesos de interoperabilidad, las que lleven a cabo la tareas de identificar, relacionar y presentar la información. Precisamente una de las razones de la propuesta es superar las limitaciones que se encuentran los motores de búsqueda al procesar documentos con información textual poco estructurada y sin descripción normalizada.
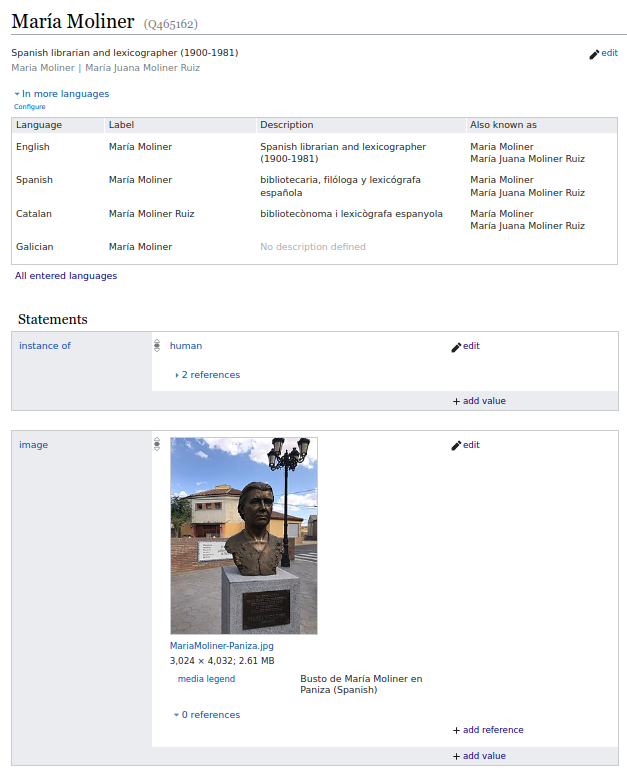 Fig. 4. María Moliner etiquetada semánticamente en Wikidata (fuente original).
Fig. 4. María Moliner etiquetada semánticamente en Wikidata (fuente original).
Los proyectos de web semántico se están centrando en etiquetar y hacer interoperables grandes silos de datos etiquetados, como los catálogos, y en la creación de ontologías, como recursos de descripción de entidades. A través de estas técnicas es posible relacionar informaciones de manera automática, integrándola desde diferentes recursos, y eliminando las posibles inconsistencias o confusiones entre las entidades. Sin embargo, y en lo que concierne a la búsqueda de información en internet, su uso aún no se ha hecho común, y los motores sólo hacen un aprovechamiento limitado, principalmente de los etiquetados de metadatos.
Financiado por el Ministerio de Educación y Formación Profesional y por la Unión Europea - NextGenerationEU
![]()
2. Los motores de búsqueda: funcionamiento
Este bloque explica la estructura y funcionamiento de los motores de búsqueda para internet.
2.1. Captura de información
La identificación y captura de información es llevada a cabo por el robot o spider. El robot de búsqueda es una herramienta de software que rastrea internet, con la finalidad de localizar e identificar nuevas páginas y documentos, y la de detectar si se han producido cambios o modificaciones en otras que ya hubiese localizado previamente. Las nuevas páginas encontradas son utilizadas, a su vez, como punto de partida para descubrir nueva información, utilizando los enlaces que contienen.
 Fig. 5. Arquitectura de un motor de búsqueda en internet (fuente original)
Fig. 5. Arquitectura de un motor de búsqueda en internet (fuente original)
Cuando un robot localiza una nueva página o documento, procede a enviar una copia del mismo, o de partes seleccionadas, al programa de representación e indización que utiliza el motor de búsqueda, y que es el encargado de generar una representación de la página o documento para su incorporación a la base de datos. Sus características permiten que los responsables de la programación de los robots establezcan parámetros para su actuación, atendiendo a factores como tamaño del web que lo contiene, tiempo desde la última actualización en la base de datos, “popularidad” de los documentos en las búsquedas de los usuarios, etc.
Aunque no existe una norma estándar para la arquitectura y actividad de los robots, hay que considerar que en 1993 y 1994 ya se recomendó un estándar de facto, que no ha sido aplicado en su totalidad. Las Guías para Autores de Robots y las Normas para la Exclusión de Robots establecen los principios de actividad responsable, eficiencia en la utilización de recursos y limitaciones de acceso a los servidores de información. Estos principios establecen la posibilidad de que los responsables de un sitio web excluyan al sitio en cuestión de ser recopilado y, en consecuencia, de ser incluidos sus contenidos en los índices que los motores de búsqueda usan para las tareas de recuperación de información.
Material complementario
Financiado por el Ministerio de Educación y Formación Profesional y por la Unión Europea - NextGenerationEU
![]()
2.2. Procesamiento y recuperación de información
Una vez que el motor recibe la copia del documento que le remite el robot, se procede a su representación o indización. Esto es debido a que las páginas o documentos no pueden integrarse directamente en las bases de datos. Previamente es necesario llevar a cabo un proceso de indización automática, con la finalidad de crear una representación del contenido informativo. Esta indización puede realizarse desde diferentes enfoques, aunque el más utilizado es el modelo que se basa en la representación de los documentos como vectores, dentro de un espacio vectorial.
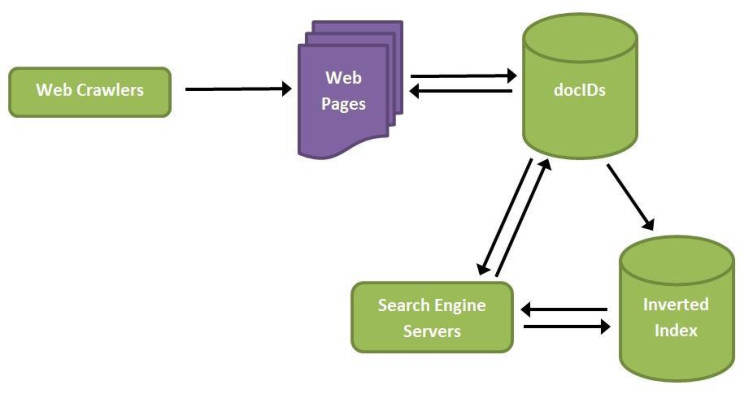 Fig. 6. Esquema de funcionamiento del proceso de captura y representación en un motor de búsqueda (fuente original).
Fig. 6. Esquema de funcionamiento del proceso de captura y representación en un motor de búsqueda (fuente original).
Toda esta información se almacena en grandes bases de datos, que además pueden incorporar a cada representación otros datos, como el url (Universal/Uniform Resource Locator) de cada página o documento, o dar prioridad en los vectores a algunos elementos específicos, como puedan ser los metadatos detectados.
Financiado por el Ministerio de Educación y Formación Profesional y por la Unión Europea - NextGenerationEU
![]()
2.3. Presentación de resultados
La explotación del contenido de los motores se lleva a cabo mediante la consulta a través de una interfaz web. Los motores suelen ofrecer una interfaz sencilla o simplificada, que presenta la típica caja de diálogo para introducir una expresión, y una interfaz avanzada, que ofrece más opciones para establecer parámetros que refinan y limitan los ámbitos de búsqueda. Estas interfaces permiten enviar al motor de recuperación la expresión o ecuación de búsqueda formulada por el usuario. Este componente, sobre el que los motores son poco dados a ofrecer información, es la clave para la recuperación de información, ya que es el responsable de traducir la ecuación de búsqueda, en formato textual, a una expresión matemática que es la confrontada con el contenido de la base de datos.
La presentación de las respuestas obtenidas se basa en la presentación de listados de respuestas, ordenados de mayor a menor relevancia según cálculo propio del motor de recuperación. El conocido PageRank de Google es un algoritmo de ordenación que utiliza diferentes criterios para asignar la relevancia. Estas listas, generadas de forma dinámica como resultado del proceso de interrogación, contienen el listado de respuestas, indicando para cada una de ellas su título, url, fecha, tamaño, un breve resumen que suele corresponder a las primeras líneas o a las cabeceras del contenido, y otros datos. Los resultados se muestran ordenados según la pertinencia dada a cada documento, comparándolo con la expresión formulada por el usuario. En los motores también se incorporan opciones que ofrecen acceso a resultados similares o del mismo tipo, utilizando para ello precisamente la distancia entre los vectores que representan documentos dentro del espacio vectorial. Finalmente, tras el listado de respuestas se ofrece de nuevo la interfaz de interrogación, para que el usuario pueda reformular la expresión de búsqueda si es necesario.
Los motores de búsqueda, excepto algunas excepciones, son un negocio. Están sostenidos y operados por empresas comerciales, lo que supone que junto a los resultados de una búsqueda es posible encontrar enlaces que no son resultados de esa búsqueda. Hay que diferenciar entonces entre lo que se llama “búsqueda orgánica”, y lo que no. Búsqueda orgánica es el conjunto de resultados que no son anuncios, y que proceden de un proceso de búsqueda y presentación neutral. En los listados de respuestas, aquellos resultados que no son orgánicos, que son publicidad, deben presentarse siempre identificados como “Anuncio”.
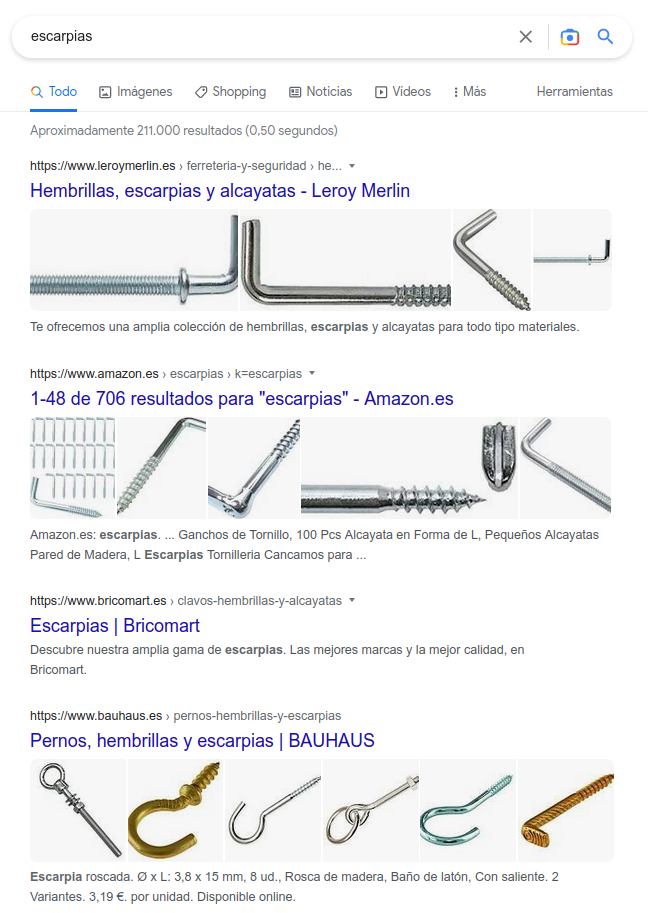 Fig. 7. Una búsqueda poco orgánica (fuente original).
Fig. 7. Una búsqueda poco orgánica (fuente original).
Progresivamente, los motores han ido añadiendo más prestaciones de cara a los usuarios, como el mantenimiento del historial de búsqueda, el establecimiento de alertas personalizadas con nuevos resultados sobre una búsqueda dada, o la posibilidad de compartir resultados con otros usuarios.
Financiado por el Ministerio de Educación y Formación Profesional y por la Unión Europea - NextGenerationEU
![]()
3. Los principios básicos de recuperación de información
Se explica el modelo básico de proceso de búsqueda, así como la formación de ecuaciones y el uso de operadores.
3.1. El proceso de búsqueda
Los procesos de búsqueda de información distan de ser perfectos y pautables. Cada proceso es diferente, y se ve afectado por numerosos factores, tanto internos del propio proceso y de la herramienta utilizada, como externos, relacionados con el propio usuario y con sus contextos social, educativo o técnico. La necesidad de respuestas rápidas, o el nivel de profundidad deseado, también influyen en las decisiones que el usuario toma en cada momento. No debe olvidarse que, aunque se trata de un proceso mediado tecnológicamente, es el usuario el que toma decisiones que afectan al propio proceso. Finalmente, la satisfacción que el usuario siente o expresa con el proceso también es dependiente de factores intrínsecos al propio usuario.
Un aspecto que es necesario destacar antes de iniciar un proceso de búsqueda es el problema que puede plantear la transferencia entre tres niveles de expresión:
- En primer lugar, el usuario tiene un modelo mental de su carencia o necesidad de información, pero es necesario que traslade ese modelo al lenguaje formal. Esta primera transformación ya puede suponer un riesgo de pérdida de elementos.
- En segundo, el usuario transformará la expresión en lenguaje formal en una expresión en el lenguaje de búsqueda que utiliza el motor (la clásica expresión o ecuación de búsqueda).
- Finalmente, el motor transformará esa expresión de acuerdo al algoritmo que utilice internamente para representar la información. Las respuestas que ofrezca responderán a esta última transformación, y podrán, a su vez, responder o no a la necesidad original del usuario.
Los siguientes párrafos recogen una propuesta clásica de un proceso de recuperación; pero debe recordarse siempre que la búsqueda y recuperación de información no son procesos y actividades exactas: pueden encontrarse varios procesos y soluciones distintas para el mismo problema:
- Planteamiento del tema y nivel de conocimientos: Este trabajo permite definir con claridad cuál es la necesidad de información del usuario. Debe establecer claramente cual es el objetivo de interés, así como los límites del mismo. Hay objetivos que pueden parecer adecuados, pero que en realidad necesiten un refinamiento; deben plantearse todas las posibles situaciones que puedan darse, y pensar en varias aproximaciones al problema. Se debe establecer cual es el propio nivel de conocimientos sobre el tema. Si el nivel de conocimientos es adecuado, se podrá abordar el problema de la fiabilidad con mayores garantías. En cualquier situación, esta fase debe dar como resultado una formulación clara e inequívoca del objetivo de su búsqueda.
- Identificación de los tipos de información: El web contiene diferentes tipos de información, tanto por el tipo de fichero que los contiene, como por el objetivo y finalidad de las páginas web y de los creadores de las mismas. Es necesario establecer la posible utilidad de cada uno de estos tipos de documentos, y no desdeñar ninguno a priori, ya que por exploración se puede encontrar información complementaria que resulte pertinente.
- Selección de los recursos de información y de las herramientas de consulta: La selección de los recursos de información, es decir, motores de búsqueda genéricos, recursos de información especializada, etc. a utilizar, es de suma importancia. Dependiendo del contexto de actividad del usuario, en muchas ocasiones el conocimiento de estas fuentes especializadas es directo, sin necesidad de acudir a una búsqueda previa en un motor generalista.
- Ejecución de las expresiones o ecuaciones de búsqueda, evaluación e iteración: Se trata de la formulación y ejecución de las expresiones o ecuaciones de búsqueda en el motor o recursos que se trate (correspondería con las segunda y tercera transformaciones indicadas previamente). Es un proceso iterativo: recepción de respuestas, valoración de resultados, cambio o refinamiento de la ecuación, nueva ejecución, nuevas respuestas, nueva valoración… (esta fase se desarrolla con más detalle en el apartado siguiente).
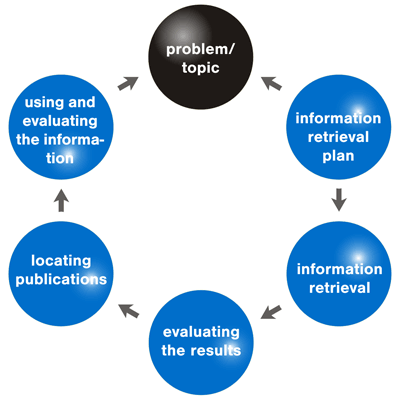 Fig. 8. Proceso genérico de búsqueda de información (fuente original).
Fig. 8. Proceso genérico de búsqueda de información (fuente original).
El proceso acabará cuando el usuario considere que su necesidad de información puede ser resuelta con los documentos y la información obtenidos. Después del uso de motor de búsqueda, deberán realizarse la tareas de acceso a los originales, valoración de contenido, selección y uso en virtud de la necesidad original.
Videotutorial: Los 4 pasos de la búsqueda de información (2018)
Financiado por el Ministerio de Educación y Formación Profesional y por la Unión Europea - NextGenerationEU
![]()
3.2. Ecuaciones y operadores
La operativa más conocida en la búsqueda de información es la formulación de expresiones o ecuaciones de búsqueda. Como se ha explicado en el apartado anterior, en un proceso bien planteado ésta debería ser una fase más, y debería ir precedida de una adecuada planificación. En la actualidad, los usuarios suelen adoptar un enfoque de “escribir y esperar”: escriben en la interfaz de consulta una palabra o frase que consideran adecuada, y esperan los resultados. Suelen evaluar los 10 primeros, o lo que muestra la primera página de resultados, y en pocas ocasiones avanzan más allá. Tampoco suelen acudir al uso de operadores para mejorar los resultados, ya que normalmente cambian los términos o frase usada, con la esperanza de obtener mejores resultados. El proceso de interrogación suele organizarse alrededor de tres tareas principales:
- Formulación de la ecuación, ejecución y recepción de respuestas: En ella se introduce en la interfaz la expresión que reúne los términos elegidos, y los operadores que establecen las relaciones existentes entre aquellos. Los motores ofrecen siempre páginas de ayuda, en las que explican las posibilidades del lenguaje de interrogación que usan, y suelen incluir ejemplos. También ofrecen interfaces simples y avanzadas para formular las ecuaciones. La recomendación sería utilizar las interfaces avanzadas, ya que van a ofrecer más potencial y parámetros que ayudan a perfeccionar las ecuaciones y a obtener resultados ajustados.
- Visualización y preselección de respuestas pertinentes: Se trata de la exploración de las respuestas obtenidas y, en su caso, la consulta de los documentos originales. Los datos que ofrece el listado se utilizan para llevar a cabo una primera selección de aquellas respuestas que parecen relevantes, y para desechar aquellas que no sean adecuadas. Acudir a consultar el documento original exige establecer una conexión con el mismo, lo que lleva a un cambio de la interfaz de visualización y a la pérdida del listado de respuestas por efecto de la navegación. Para evitar esa pérdida de contexto, y evitar la sobrecarga cognitiva, es recomendable establecer la conexiones en ventanas o pestañas nuevas. Si el documento al que se ha accedido interesa, la recomendación es guardar el url de acceso en funcionalidades de marcadores o herramientas similares.
- Replanteamiento de estrategias: Si tras analizar las quince o veinte primeras respuestas no se han obtenido resultados satisfactorios, es necesario modificar la búsqueda. El cambio puede referirse a las ecuaciones utilizadas, o al motor o herramienta seleccionado, o a ambas cosas. Si el número de respuestas obtenido es muy elevado, y los primeros resultados son poco pertinentes, muy generales, debe formularse una nueva ecuación de búsqueda, con más condiciones y limitaciones. En el caso contrario, con nulo o escaso número de resultados, puede suceder que a) si la ecuación no es restrictiva, entonces no hay documentos, o los documentos no contienen esos términos; b) que la ecuación sea demasiado restrictiva, con demasiadas condiciones. Para estos casos hay que experimentar con una ecuación con menos condiciones, y usar términos sinónimos o similares a los usados anteriormente.
Los lenguajes de interrogación utilizan una estructura en la que participan órdenes, operadores y operandos, los cuales, combinados según un conjunto de reglas sintácticas establecidas en el propio lenguaje, permiten formular expresiones de interrogación que reciben el nombre común de ecuaciones. Los lenguajes de recuperación que utilizan los motores u otros recursos y fuentes de información están disponibles para el usuario a través de una interfaz propia, que limita las posibilidades de construcción de expresiones, aunque teóricamente sin perjuicio de la necesaria complejidad. En realidad, esta interfaz supone una simplificación de esas posibilidades, porque no suele mostrar todos los operadores disponibles. Los operadores disponibles para la recuperación de información en internet pueden clasificarse de la siguiente forma:
- Operadores booleanos: todos los motores admiten los tres operadores booleanos básicos (Y, O, NO - AND, OR, NOT). Esto permite construir ecuaciones basadas en la lógica booleana, y la resolución de las mismas mediante la aplicación de la teoría de conjuntos. Al igual que en los sistemas clásicos de recuperación de información, los operadores booleanos trabajan considerando exclusivamente la presencia o ausencia en los documentos de los términos incluidos en la ecuación. Algunos motores admiten los llamados “pseudoboleanos”, con los símbolos +/-, que obligan a la presencia o ausencia del término al que preceden.
 Fig. 9. Operadores booleanos de conjuntos (fuente original).
Fig. 9. Operadores booleanos de conjuntos (fuente original).
- Operadores de frase o expresión: de la misma forma, casi todos admiten el uso de frase o expresión exacta, generalmente entrecomillada, o mediante la activación de una casilla o botón específico para tal fin. En realidad, se trata de la utilización de un operador de posición relativa, el de adyacencia, con la limitación de respetar el orden de aparición de los términos.
- Operadores de límite: dentro de lo que los motores identifican en sus interfaces como límites, tienen cabida un dispar conjunto de operadores, que varían notablemente de unos motores a otros. Dentro de estos límites es posible identificar, por ejemplo, operadores de rango (relacionados con fechas, por ejemplo), o truncamientos (palabras de misma raíz, búsqueda por lema o raíz de los términos).
- Operadores de posición o campo: algunos motores incorporan la posibilidad de utilizar el contenido de determinadas etiquetas HTML, presentes en los documentos, como campos específicos, de modo que pasan a actuar como operadores de posición absoluta. Si los términos buscados aparecen dentro de un título, un enlace u otra etiqueta significativa, se deduce que el contenido del documento es más relevante.
- Operadores de relación entre documentos: una posibilidad de sumo interés es la disponibilidad de operadores que emplean los enlaces hipertextuales entre documentos presentes en los mismos, para recuperar documentos enlazados, tanto en destino, como en origen. La utilización de los mismos nos permite realizar búsquedas por exploración, tras localizar un documento que actúa como punto de partida o “semilla”.
- Operadores de ejemplo: bajo este nombre se agruparían los algoritmos que hacen posible localizar páginas o recursos web que ofrecen un alto nivel de similaridad con un ejemplo o patrón que ha sido identificado por el usuario como altamente relevante. El ejemplo clásico sería la funcionalidad “Más como éste” disponibles en los motores de búsqueda.
Videotutorial: Estrategias de búsqueda de información (2020)
Financiado por el Ministerio de Educación y Formación Profesional y por la Unión Europea - NextGenerationEU
![]()
3.3. Interpretación de resultados. Límites
En primer lugar, debe tenerse en consideración que puede existir cierto nivel de disfunción entre el contenido informativo real de una página web, en virtud de las características de los documentos digitales, que pueden cambiar de manera dinámica muy rápidamente, y la representación que se obtiene de ella mediante los procesos de indización automática que llevan a cabo los motores.
Una vez considerado esto, y tras llevar a cabo una búsqueda, es necesario analizar la pertinencia y relevancia de los resultados obtenidos. Una alta pertinencia se caracteriza por la recuperación de los documentos adecuados a la información que se deseaba obtener, evitando la introducción de otros que puedan distorsionar el conjunto, impidiendo una correcta recuperación de la información. En sistemas de tratamiento y recuperación de información documental, ésta debe ser exacta, exhaustiva, precisa, oportuna, íntegra y significativa. Por contra, el silencio (falta de documentos) y el ruido (exceso de documentos, muchos de ellos no significativos) caracterizan a un bajo nivel de pertinencia. Debe tenerse en cuenta que la pertinencia hace referencia a la correspondencia entre la ecuación formulada y los resultados obtenidos, lo que quiere decir que un resultado puede ser pertinente… pero no ser relevante para el usuario, ya que éste puede conocer su contenido previamente, o no ajustarse con exactitud a lo que necesita. Será el usuario final, durante la evaluación de las respuestas, el que decidirá sobre la relevancia o no de un resultado o de una información para resolver la necesidad que tenía planteada.
Videotutorial: Criterios de búsqueda de información en internet (2020)
Como resultado del análisis anterior, cabe plantearse la adecuación de la respuesta obtenida a lo esperado. Pueden darse dos situaciones, ante las cuales deben adoptarse diferentes acciones. En un primer caso, puede suceder que el resultado de la ecuación sea demasiado escaso. Entonces procede ampliarla, lo cual puede hacerse con la utilización de términos más genéricos, sinónimos, o ampliación de truncamientos. En un segundo caso, si el resultado obtenido es excesivamente amplio, deben utilizarse medidas contrarias: utilización de términos más específicos, reducción de truncamientos, etc.
Por último, en entornos digitales puede producirse un problema que afecta a los procesos de búsqueda. Al trabajar en un entorno bidimensional a través de la interfaz de un navegador, la consulta puede quedar atrás al acudir a consultar una respuesta. La propia consulta de la respuesta puede lleva a iniciar un proceso de exploración de otras páginas o documentos web. En un momento puede producirse una desorientación cognitiva, en la cual el usuario pierde el foco de referencia (la búsqueda original) y se ve inmerso en una navegación de continuos saltos adelante y atrás. Es necesario prever ese potencial problema, y adoptar pautas de navegación que limiten las complicaciones que puedan surgir durante el proceso de comprobación y selección de resultados.
Financiado por el Ministerio de Educación y Formación Profesional y por la Unión Europea - NextGenerationEU
![]()
4. Motores generalistas: Google y DuckDuckGo
Este bloque se centra en el uso de las funcionalidades de Google y de DuckDuckGo para buscar información en internet.
4.1. Búsqueda con Google
Google, lanzado en 1998, supuso un avance en los motores de búsqueda en internet. Haciendo bandera de la simplicidad de uso, con su interfaz simplificada frente a otros motores, y haciendo uso del algoritmo PageRank, en pocos años se convirtió en el buscador de referencia, desbancando al resto de la competencia. Su éxito, durante las dos pasadas décadas, le permitió adquirir e integrar un buen número de empresas con servicios interesantes, que incorporó como propios (por ejemplo Writely, que transformó en Google Docs), hasta convertirse en un gigante de internet.
 Fig. 10. Interfaz simple de Google.
Fig. 10. Interfaz simple de Google.
En la actualidad más del 95% de las consultas utilizan la interfaz simple de Google, a través de la cual formulan búsquedas principalmente basadas en uno o dos términos, o en el uso de una frase. Diferentes estudios de comportamiento informacional han demostrado que los usuarios raramente pasan a la segunda página de resultados, conformándose con los mostrados en la primera, o rehaciendo la búsqueda en todo caso. No debe olvidarse, como se ha recogido en un apartado anterior, que el motor de búsqueda de Google es un producto comercial, de código propietario, y que los resultados de la búsqueda orgánica pueden quedar difuminados entre anuncios de productos o servicios relacionados con la consulta efectuada.
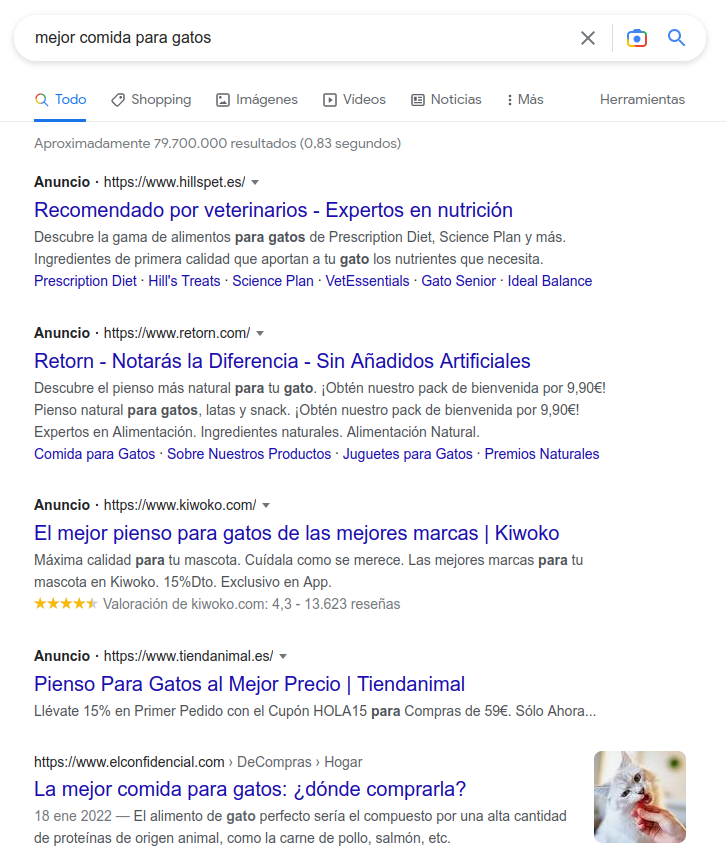 Fig. 11. Preponderancia de anuncios frente a búsqueda orgánica (fuente original)
Fig. 11. Preponderancia de anuncios frente a búsqueda orgánica (fuente original)
Aunque esta interfaz lleva a que los usuarios simplifiquen, en realidad Google permite usar operadores booleanos y otros tipos de operadores en la expresión, así como el uso de paréntesis para fijar el orden de ejecución de operaciones cuando en una ecuación se combinan varios términos con diferentes operadores. Google ofrece, por el momento, hasta 42 operadores que permiten refinar y limitar las búsquedas. Las posibilidades de combinación son muy amplias, pero entre los operadores no hay ninguno que permita eliminar de los resultados los anuncios. Como última solución, puede acudirse a software de terceros que puede bloquear los anuncios, pero no se puede asegurar un resultado satisfactorio. En lo que concierne a la accesibilidad, la página de respuestas está preparada para su uso con las técnicas más comunes.
Videotutorial: Cómo usar operadores booleanos correctamente (2019)
El historial de las búsquedas realizadas en Google queda registrado si el usuario así lo desea. También puede utilizarse para hacer un seguimiento de los procesos de búsqueda, y repetirlas si se considera oportuno. Para ello es necesario que se acceda a través de una cuenta de Google, y que se establezcan los parámetros adecuados a través de “Mi actividad”. Se pueden controlar la duración y borrado del historial, y la sincronización entre diferentes dispositivos, por ejemplo.
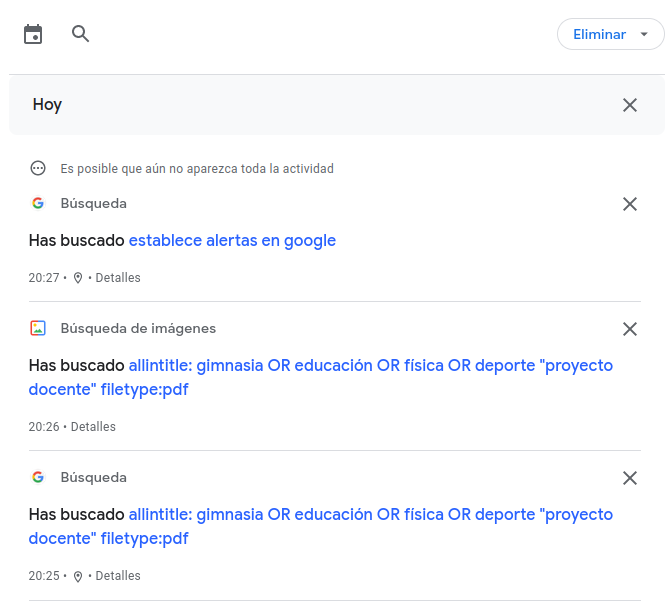
Fig. 12. Historial de búsquedas
Videotutorial: Buscar en Internet. la barra superior de Google (2022)
Material complementario
Financiado por el Ministerio de Educación y Formación Profesional y por la Unión Europea - NextGenerationEU
![]()
4.2. Búsqueda avanzada con Google
La interfaz de búsqueda avanzada es poco utilizada en las búsquedas en Google, como se señaló en el apartado anterior. Sin embargo ofrece un gran potencial para refinar y limitar los resultados de búsqueda. Esto es especialmente valioso cuando el número de resultados es muy elevado (teniendo en cuanto que casi siempre nos devuelve varios miles de respuestas) o los resultados muestran mucho ruido o poca relevancia para la necesidad de información del usuario. El principal problema es que Google la oculta entre sus opciones, porque, al parecer, no está muy interesado en que los usuarios sepan de su existencia. Para poder acceder a la misma, es necesario desplegar el menú emergente que aparece tras pulsar sobre el icono de “engranaje” que se muestra en la página, o bien conocer el url que facilita el acceso directo.
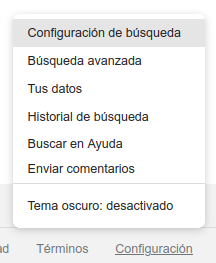 Fig. 13. Menú emergente con el enlace la búsqueda avanzada
Fig. 13. Menú emergente con el enlace la búsqueda avanzada
La interfaz avanzada ofrece un formulario dividido en dos áreas. En la superior se pueden introducir términos y expresiones, que Google transformará en la típica ecuación de búsqueda con términos relacionados mediante operadores booleanos y de rango. En el área inferior se pueden establecer límites para la búsqueda, como idiomas de la página, fecha de actualización, formato de documento… En este área deben destacarse el filtro llamado “los términos que aparecen:”, que no deja de ser un clásico operador de posición absoluta, basado en la presunción de que la aparición de los términos en el título o en los enlaces significan que la página en cuestión es más relevante para la búsqueda del usuario que otras en las que simplemente aparecen en el texto.
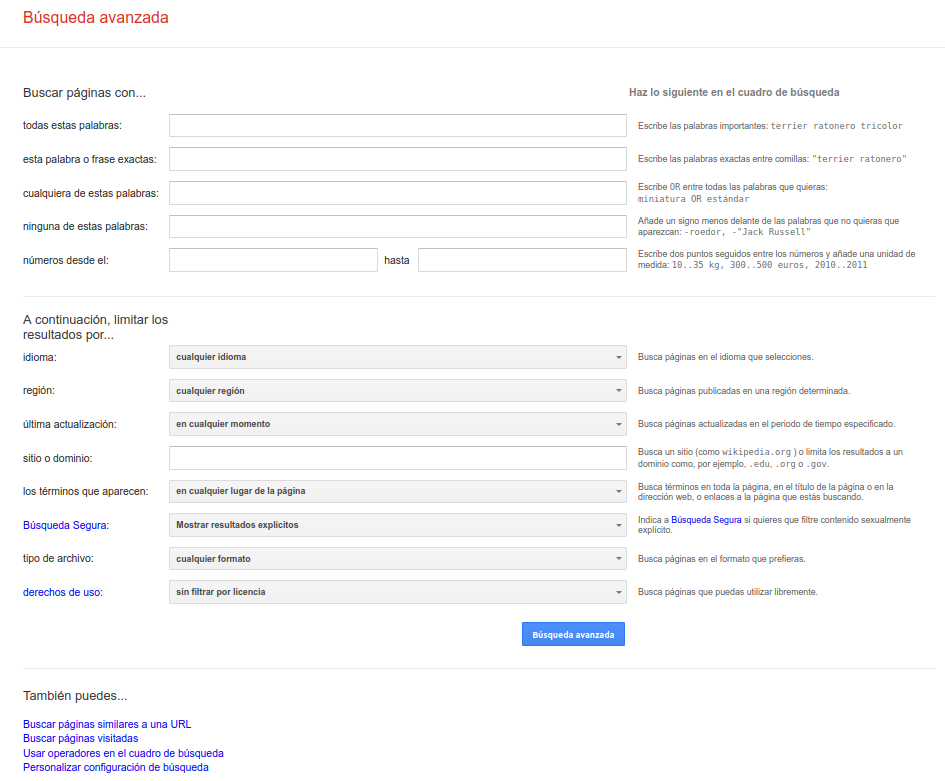
Fig.14. Interfaz de Búsqueda Avanzada
La búsqueda de imágenes también disfruta de la posibilidad de lleva a cabo una búsqueda avanzada. En este caso, las opciones están orientadas a características de las imágenes. No hay que olvidar, por otra parte, que buena parte de la descripción de las imágenes se obtiene analizando el título, la leyenda o el texto que las rodea, lo que no deja de ser un caso especial de tratamiento textual.
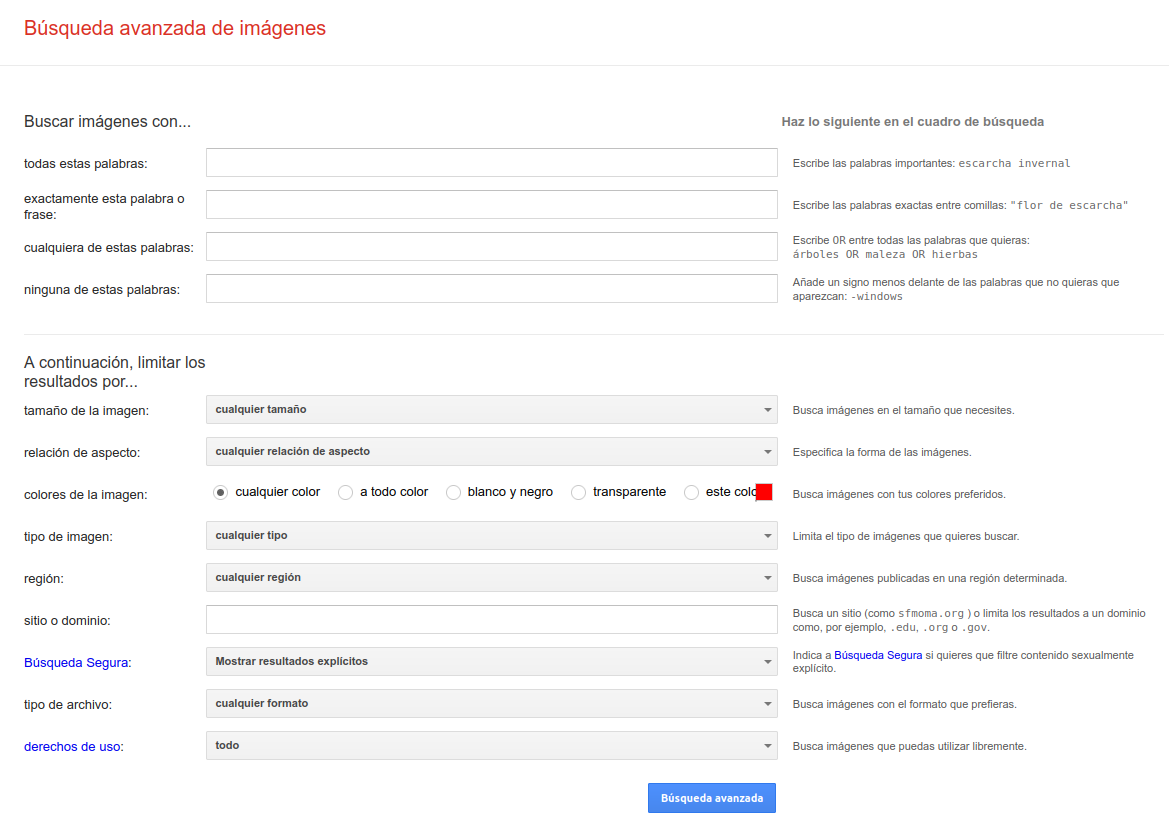
Fig. 15. Interfaz de Búsqueda Avanzada para imágenes
Cuando lo que interesa es recibir avisos con nuevas páginas o documentos que cumplen con las condiciones que se han expresado en una ecuación de búsqueda, es necesario establecer una alerta. La interfaz más simple permite formular una expresión de búsqueda: las alertas se envían automáticamente al correo electrónico del usuario. Si se despliega el menú emergente “Mostrar opciones” pueden definirse varios parámetros de contenidos y actualización. En cualquier momento es posible volver a alertas y modificar o borrar lo necesario.
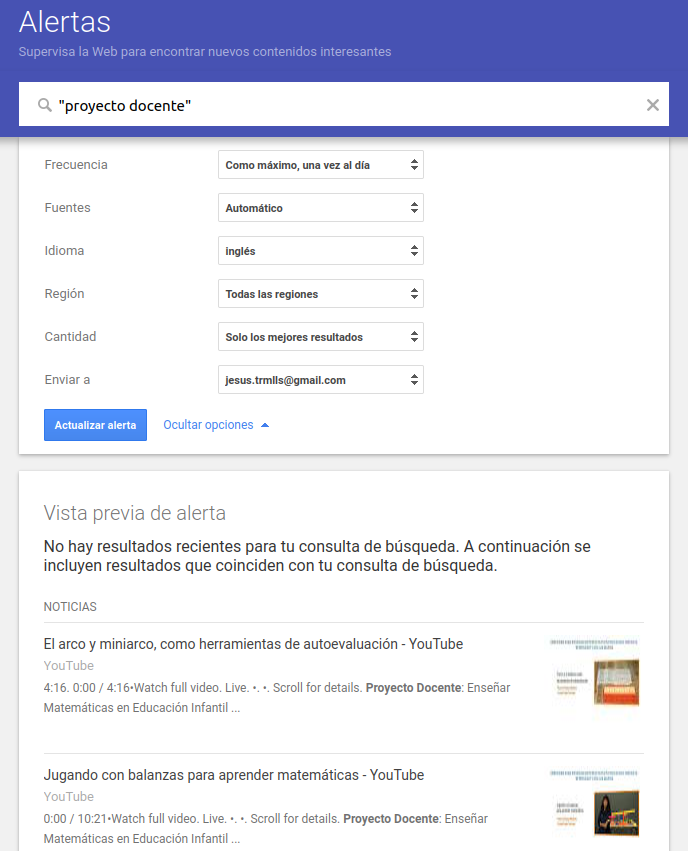 Fig. 16. Interfaz de Alertas en Google
Fig. 16. Interfaz de Alertas en Google
Videotutorial: Buscar en Internet. Configuración de Google (2022)
Financiado por el Ministerio de Educación y Formación Profesional y por la Unión Europea - NextGenerationEU
![]()
4.3. Búsqueda con DuckDuckGo
DuckDuckGo es otro motor de búsqueda genérico. A diferencia de la orientación comercial de Google, DuckDuckGo respeta la privacidad y se compromete a no usar con otros fines los datos de las búsquedas de los usuarios. La mayor parte de sus aplicaciones de escritorio y de las herramientas web son software libre, o están basadas en herramientas libres.

Fig. 17. Interfaz de DuckDuckGo
Este motor sólo ofrece una interfaz simple: una caja de diálogo en la que formular las expresiones o ecuaciones de búsqueda. En consecuencia, tampoco ofrece una interfaz de búsqueda avanzada. Ofrece un conjunto básico de operadores booleanos y alguno de posición absoluta o de tipo de formato, que permiten formular ecuaciones de búsqueda de complejidad media.
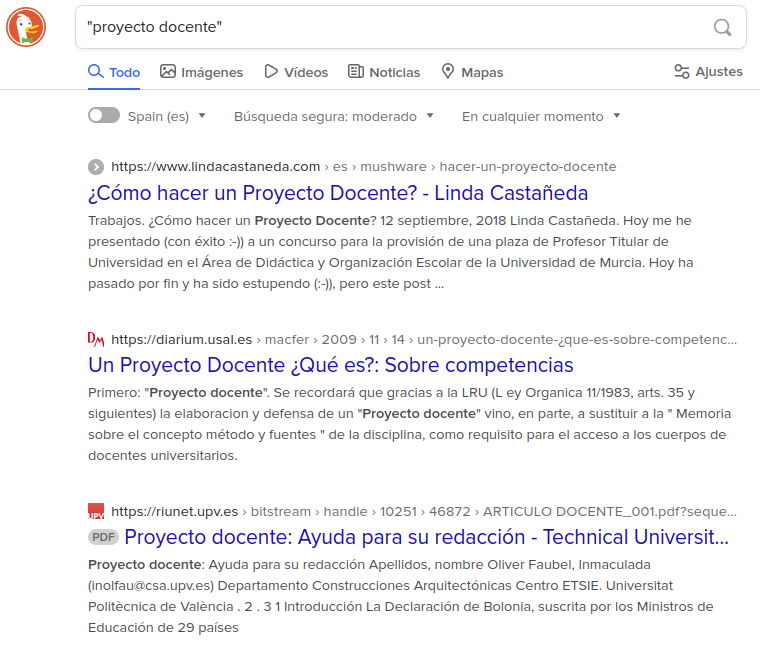
Fig. 18. Ejemplo de listado de respuestas de DuckDuckGo
El listado de respuestas está libre de publicidad, y por ello todas las respuestas corresponden a búsqueda orgánica. La interfaz es similar, pero no ofrece funcionalidades de personalización ni de alertas. Aunque su base de datos es menor que la de Google, los resultados suelen ser bastante ajustados. Si el principal interés es la privacidad y evitar la publicidad, esta la opción recomendada. En cualquier caso, para obtener una cobertura mayor sería recomendable combinarla con una búsqueda similar en Google. No consta información específica sobre la accesibilidad del servicio, más allá de algunos parámetros de legibilidad.
Videotutorial: ¡TRUCOS BÁSICOS QUE DEBES USAR EN DuckDuckGo!
Financiado por el Ministerio de Educación y Formación Profesional y por la Unión Europea - NextGenerationEU
![]()
5. Información académica y técnica: Google Académico
Google Académico (Scholar) es el motor especializado de Google que se centra en publicaciones académicas.
5.1. Contenidos de Google Académico
Google entró en el campo de los motores de búsqueda especializados en contenidos científicos y técnicos cuando lanzó su servicio Google Académico (Google Scholar en ingles) en 2004. Se trata de un subconjunto de su amplio índice de contenidos, del cual se han seleccionado aquellos que corresponden a publicaciones académicas. Google Académico se nutre de recuperar e indizar contenidos de sitios web de revistas académicas, repositorios institucionales u otras bases de datos bibliográficas, así como de los datos sobre publicaciones que le son facilitados por editoriales de obras científicas. En muchos de estos casos las páginas y documentos originales incluyen metadatos descriptivos, por lo que los resultados de las búsquedas suelen ser mucho más precisos y relevantes que los ofrecidos por los motores genéricos. El límite principal está establecido precisamente por el tipo de documento que cubre: publicaciones académicas.
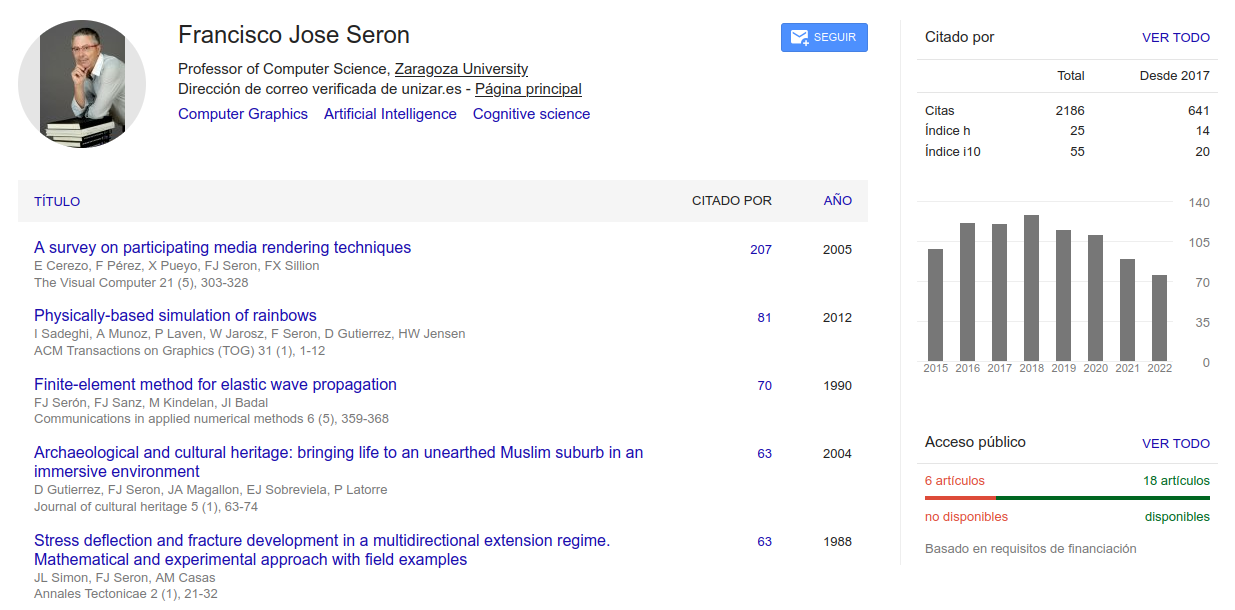
Fig. 19. Perfil de investigador en Google Académico (fuente original)
Esa limitación resulta ser, a su vez, la base de su gran potencial. La cantidad de publicación científica que recoge, a nivel mundial, ofrece una cobertura que supera a la que ofrecen otras bases de datos referenciales de pago, como Web of Science o Scopus. Esto ha favorecido que Google Académico se utilice, además, en estudios sobre impacto y difusión de la ciencia, a través de estudios bibliométricos. Un buen número de investigadores, de todos los campos del saber, han aprovechado las funcionalidades que ofrece Google Académico para crear perfiles personalizados en los que recoger sus trabajos, y poder mostrar su impacto.
Material complementario
Financiado por el Ministerio de Educación y Formación Profesional y por la Unión Europea - NextGenerationEU
![]()
5.2. Búsqueda en Google Académico
Google Académico presenta una interfaz simple de búsqueda: la clásica caja de diálogo sencilla de Google. El mecanismo para formular expresiones es similar al usado en Google, pero los operadores que se pueden utilizar son limitados. Además de los booleanos, el entrecomillado busca por título, y el operador author: permite buscar por autores.
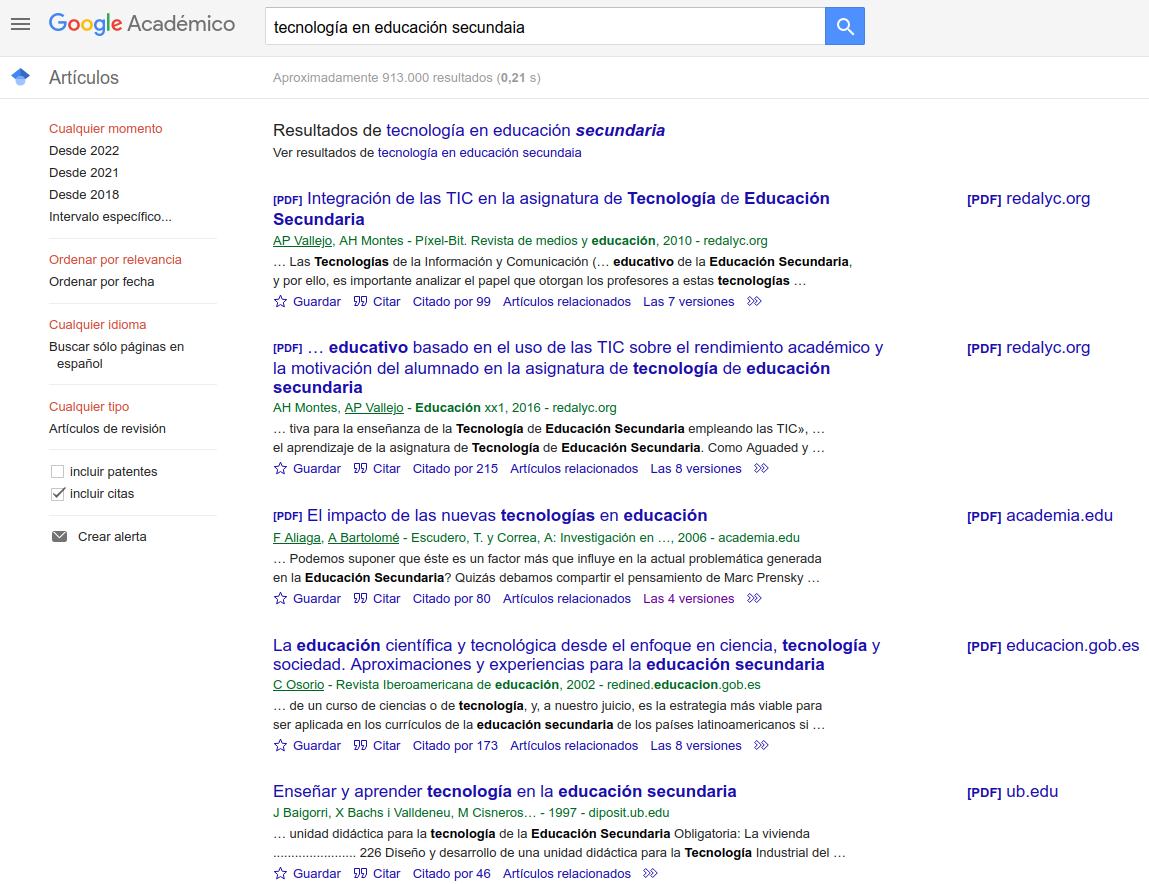
Fig. 20. Listado de respuestas en Google Académico (fuente original)
El listado de respuestas muestra diferencias respecto al del motor genérico. En primer lugar indica el formato del documento (pdf, texto, web…) seguido del título del documento, debajo del cual se despliega una línea con los autores y los datos de la publicación. Bajo ésta se muestran unas líneas de contexto de la expresión buscada. Por último, la línea final ofrece enlaces que permiten Guardar el documento en la biblioteca personal, Citar en diferentes estilos bibliográficos (APA, ISO 690 y MLA, o exportar los datos a varios formatos de intercambio para gestores de referencias), saber el número de veces que el trabajo ha sido Citado en otras publicaciones, ver otros Artículos relacionados temáticamente con éste, y, por último, ver las diferentes Versiones del documento, si las hay. Si existe una versión que puede consultarse y descargarse de manera abierta y gratuita, a la derecha se muestra el formato y el sitio web en el que está disponible.
A la izquierda del listado de respuesta se incluye un panel que permite establecer algunos filtros sobre los resultados obtenidos, como límites temporales, ordenación por fecha, o seleccionar artículos de revisión.
Videotutorial: Google académico. Tutorial de uso (2022)
Financiado por el Ministerio de Educación y Formación Profesional y por la Unión Europea - NextGenerationEU
![]()
5.3. Biblioteca y alertas
Google Académico ofrece dos funcionalidades para trabajar con los resultados obtenidos. La Biblioteca es un espacio o estantería virtual en la que el usuario puede ir guardando aquellas referencias o respuestas que le sean de utilidad para su trabajo. Para ello, basta con pulsar sobre el enlace Guardar que se muestra en la línea inferior de cada respuesta del listado. Para acceder a la biblioteca debe usarse el enlace Mi biblioteca, que se muestra en el menú emergente de la esquina superior izquierda de la página, aunque puede mostrarse también en otras localizaciones de la misma. Los trabajos recogidos en Mi biblioteca se muestran en un listado similar, con las opciones Citar, Etiquetar y Eliminar.
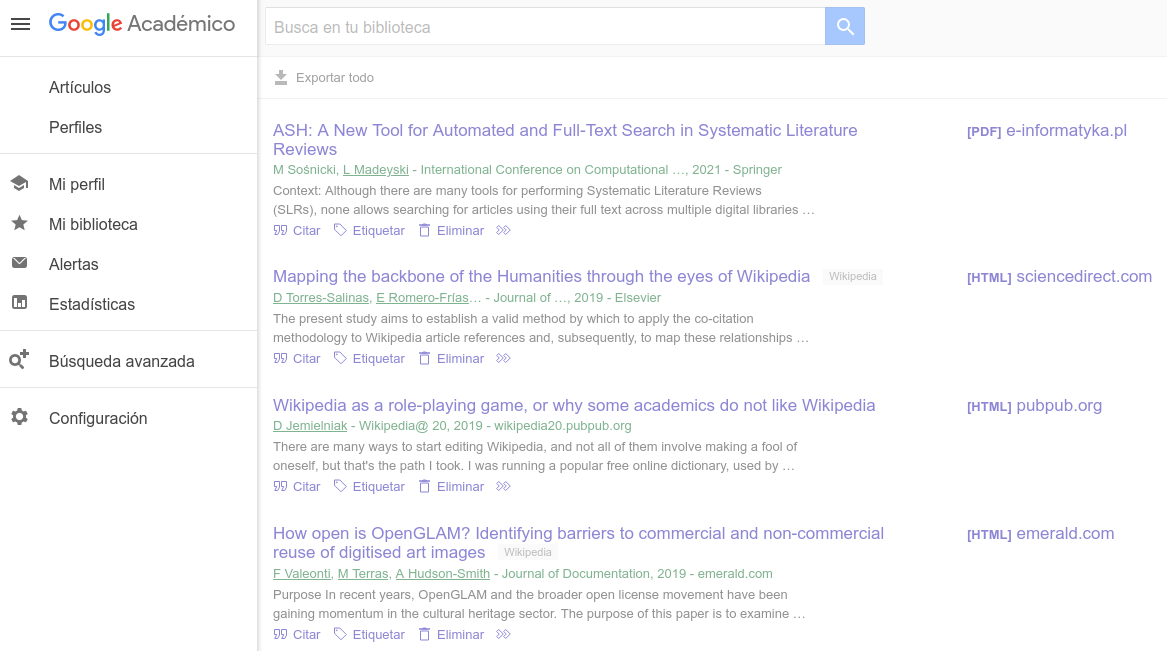
Fig. 21. Mi biblioteca en Google Académico
A las Alertas se accede desde el mismo menú emergente. Se ofrece una sucinta caja de diálogo, en la cual se puede escribir una ecuación de búsqueda, que puede incluir los operadores disponibles en Google Académico. Cada vez que se detecte un documento nuevo que responda a las condiciones expresadas en la ecuación, el usuario recibirá un correo electrónico con la información de referencia.
Financiado por el Ministerio de Educación y Formación Profesional y por la Unión Europea - NextGenerationEU
![]()
6. Producción científica en español: Dialnet
Dialnet es el recurso de referencia sobre publicaciones de ciencias humanas y sociales en español.
6.1. Contenido de Dialnet
Dialnet es una base de datos referencial especializada en la producción científica en humanidades y ciencias sociales en español. Puesta en marcha en 2002, en la actualidad es gestionada por la Fundación Dialnet. Se nutre de los datos sobre publicaciones científicas que son aportados por el conjunto de bibliotecas participantes en el proyecto, la mayoría de las cuales son bibliotecas universitarias. Gran parte del contenido corresponde a revistas, actas de congresos y tesis que no están cubiertos por Google Académico ni por Web of Science o Scopus, lo que convierte a Dialnet en el recurso de información obligado para este ámbito de publicación.
La presentación de datos sigue la metáfora de los índices tradicionales de publicaciones, por lo que pueden revisarse las revistas por años, volúmenes y números, o los contenidos de las actas de congresos. Además, Dialnet también ofrece el enlace al texto completo en abierto, cuando está disponible, de los documentos que referencia. Dialnet cumple con los estándares de accesibilidad AA.
Aunque puede consultarse libremente, la recomendación es crear una cuenta de usuario registrado, ya que las cuentas son gratuitas, y dan acceso a varias funcionalidades de interés, como son la creación de alertas, estanterías virtuales para guardar búsquedas y sus resultados, y crear listas de referencias para compartir con otros usuarios.
Material complementario
Financiado por el Ministerio de Educación y Formación Profesional y por la Unión Europea - NextGenerationEU
![]()
6.2. Búsqueda en Dialnet
La búsqueda básica en Dialnet permite formular ecuaciones sencillas que hacen uso de los operadores booleanos, de frase exacta y de truncamientos. Las funciones de búsqueda más avanzadas quedan limitadas a los usuarios de Dialnet Plus. La interfaz permite buscar directamente en los datos descriptivos de los documentos, o en el listado de revistas recogidas en Dialnet.

Fig. 22. Intefaz de búsqueda de Dialnet
Una búsqueda por Buscar documentos ofrece una respuesta que adopta la forma del clásico listado de respuestas, ofreciendo a la izquierda un panel a través del cual se pueden establecer límites por tipo de documento a los resultados de búsqueda.
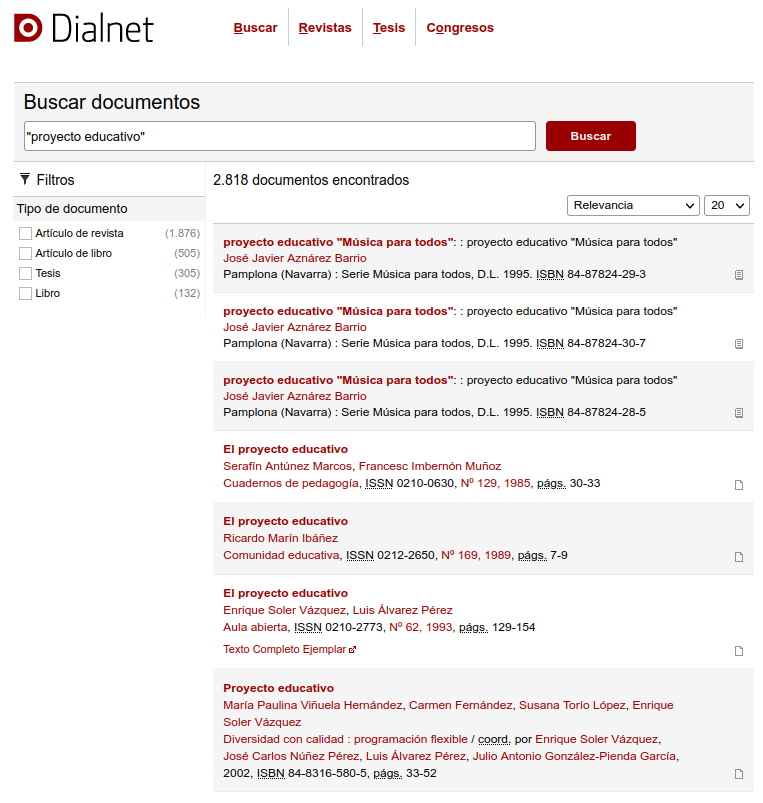
Fig. 23. Listado de respuestas en Dialnet
La pulsación sobre el título del documento lleva al registro de detalle, que contiene los datos de la publicación. Si se encuentra disponible el texto completo del documento, en acceso abierto, se incorpora además el enlace para acceder al mismo.

Fig. 24. Registro de detalle en Dialnet
Si la búsqueda se desarrolla como usuario registrado, las opciones de filtrado y trabajo posterior con los resultados obtenidos se amplia, pudiendo guardar resultados, crear listas de referencias, etc.
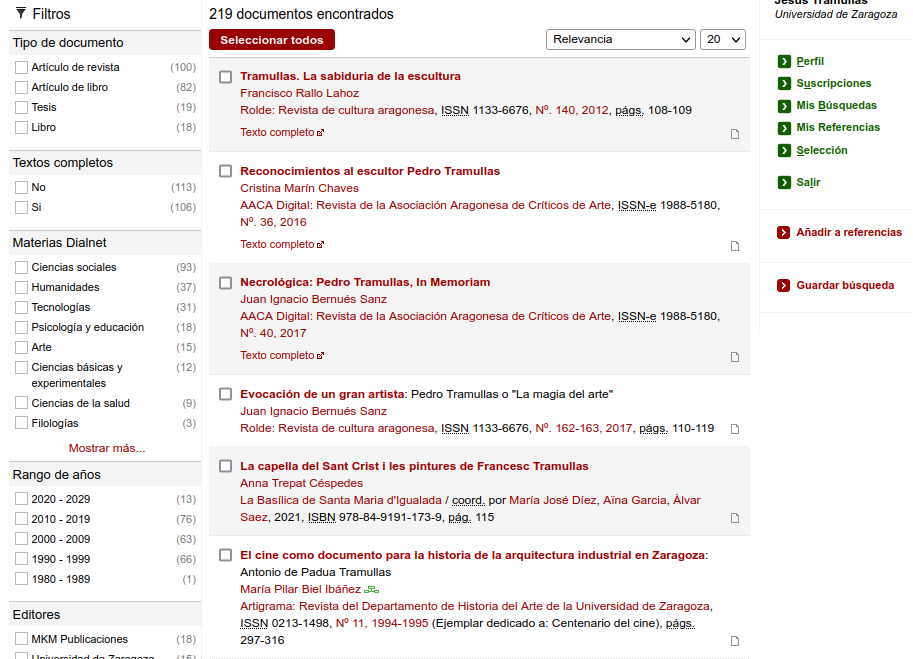
Fig. 25. Interacción como usuario registrado en Dialnet
Videotutorial: Tutorial Dialnet
Financiado por el Ministerio de Educación y Formación Profesional y por la Unión Europea - NextGenerationEU
![]()
7. Normativa LOMLOE y MRCDD relacionada
La capacidad de definir las propias necesidades de información, planificar su búsqueda, conocer las herramientas digitales para ello y configurarlas adaptándolas a las propias necesidades, así como analizar críticamente los resultados obtenidos constituyen una de las destrezas básicas del Siglo XXI en un entorno de cada vez mayor infoxicación o sobrecarga informativa y la normativa educativa así lo recoge.
El profesorado en su doble función de por un lado ciudadano digitalmente competente y por otro responsable de la alfabetización informacional de su alumnado, necesita disponer de dichas capacidades para el desarrollo de su labor profesional en la selección, curación y creación de contenidos educativos digitales y para acompañar a su alumnado en la adquisición de dichas competencias.
Se describe a continuación como estos aspectos se encuentran reflejados en la normativa educativa.
Objetivos de etapa
El Real Decreto 217/2022, de 29 de marzo por el que se establece la ordenación y las enseñanzas mínimas de la Educación Secundaria Obligatoria, establece que la Educación Secundaria Obligatoria contribuirá a desarrollar en los alumnos y las alumnas, entre otras, las capacidades que les permitan:
- Desarrollar destrezas básicas en la utilización de las fuentes de información para, con sentido crítico, adquirir nuevos conocimientos.
- Desarrollar las competencias tecnológicas básicas y avanzar en una reflexión ética sobre su funcionamiento y utilización.
Competencias clave
A su vez, tanto la Orden ECD/1112/2022, de 18 de julio, por la que se aprueban el currículo y las características de la evaluación de la Educación Primaria y se autoriza su aplicación en los centros docentes de la Comunidad Autónoma de Aragón como la Orden ECD/1172/2022, de 2 de agosto por la que se aprueban el currículo y las características de la evaluación de la Educación Secundaria Obligatoria y se autoriza su aplicación en los centros docentes de la Comunidad Autónoma de Aragón, y la Orden ECD/1173/2022, de 3 de agosto , por la que se aprueban el currículo y las características de la evaluación del Bachillerato y se autoriza su aplicación en los centros docentes de la Comunidad Autónoma de Aragón, establecen para las distintas etapas los siguientes descriptores operativos de las competencias clave lingüística y digital:
COMPETENCIA LINGUÍSTICA
- CCL3.: Al terminar la Educación Primaria el alumnado localiza, selecciona y contrasta, con el debido acompañamiento, información sencilla procedente de dos o más fuentes, evaluando su fiabilidad y utilidad en función de los objetivos de lectura, y la integra y transforma en conocimiento para comunicarla adoptando un punto de vista creativo crítico y personal a la par que respetuoso con la propiedad intelectual.
- CCL3. Al terminar la Educación Básica (Secundaria Obligatoria) el alumnado localiza, selecciona y contrasta de manera
progresivamente autónoma información procedente de diferentes fuentes, evaluando su fiabilidad y pertinencia en función de los objetivos de lectura y evitando los riesgos de manipulación y desinformación, y la integra y transforma en
conocimiento para comunicarla adoptando un punto de vista creativo, crítico y personal a la par que respetuoso con la propiedad intelectual.
- CCL3. Al terminar el Bachillerato el alumnado localiza, selecciona y contrasta de manera autónoma información procedente de diferentes fuentes evaluando su fiabilidad y pertinencia en función de los objetivos de lectura y evitando los riesgos de manipulación y desinformación, y la integra y transforma en conocimiento para comunicarla de manera clara y rigurosa adoptando un punto de vista creativo y crítico a la par que respetuoso con la propiedad intelectual.
COMPETENCIA DIGITAL
- CD1. Al terminar la Educación Primaria el alumnado realiza búsquedas guiadas en internet y hace uso de estrategias sencillas para el tratamiento digital de la información (palabras clave, selección de información relevante, organización de datos...) con una actitud crítica sobre los contenidos obtenidos.
- CD1. Al terminar la Educación Básica (Secundaria Obligatoria) el alumnado realiza búsquedas en internet atendiendo a criterios de validez, calidad, actualidad y fiabilidad, seleccionando los resultados de manera crítica y archivándolos, para recuperarlos, referenciarlos y reutilizarlos, respetando la propiedad intelectual.
- CD1. Al terminar el Bachillerato el alumnado realiza búsquedas avanzadas comprendiendo cómo funcionan los motores de búsqueda en internet aplicando criterios de validez, calidad, actualidad y fiabilidad, seleccionando los resultados de manera crítica y organizando el almacenamiento de la información de manera adecuada y segura para referenciarla y reutilizarla posteriormente.
Estos descriptores operativos se encuentran vinculados con las competencias específicas de multitud de materias de las tres etapas, lo que pone de manifiesto su carácter transversal. Dichas competencias se presuponen en el profesorado de todas las etapas, si bien es en la Etapa Secundaria Obligatoria y el Bachillerato donde se deben transmitir y trabajar de forma explícita con el alumnado.
Competencia Digital Docente
Por otro lado, la Resolución de 4 de mayo de 2022, de la Dirección General de Evaluación y Cooperación Territorial, por la que se publica el Acuerdo de la Conferencia Sectorial de Educación, sobre la actualización del marco de referencia de la competencia digital docente establece las siguientes Competencias Digitales Docentes:
- Dentro del Área 2 correspondiente a Contenidos Digitales, la competencia 2.1 Búsqueda y selección de contenidos digitales que se describe como la capacidad de localizar, evaluar y seleccionar contenidos digitales de calidad para apoyar y mejorar la enseñanza y el aprendizaje. Considerar, de forma específica, el objetivo de aprendizaje, el contexto, el enfoque pedagógico, el tipo de licencia y aspectos técnicos que garanticen la accesibilidad universal, la usabilidad y la interoperabilidad.
- Dentro del Área 6 correspondiente a Desarrollo de la Competencia Digital del Alumnado, la competencia 6.1 Alfabetización mediática y en el tratamiento de la información y de los datos que se describe como la capacidad de diseñar, implementar e integrar, en los procesos de enseñanza y aprendizaje, propuestas pedagógicas para el desarrollo y evaluación de la competencia digital del alumnado en alfabetización mediática y en el tratamiento de la información y de los datos.
Todo ello hace que los contenidos tratados en este curso se consideren de vital importancia en la formación del profesorado de cualquier etapa educativa y materia impartida.
Financiado por el Ministerio de Educación y Formación Profesional y por la Unión Europea - NextGenerationEU
![]()