1.3. El web semántico
A comienzos del siglo XXI Tim Berners-Lee y otros investigadores propusieron avanzar en la organización y recuperación de la información en el web adoptando un conjunto de métodos y técnicas que se englobaron bajo la expresión “web semántico”. En realidad, este esfuerzo está dirigido a estructurar contenidos de todo tipo de recursos y documentos web de acuerdo a un conjunto de estándares. La idea básica es incorporar datos etiquetados que sirvan para describir el contenido, el significado y la relación entre los diferentes elementos etiquetados.
Los usuarios de estos datos estructurados no son los usuarios finales: los destinatarios son las máquinas. El web semántico está diseñado para que sean las máquinas, mediante procesos de interoperabilidad, las que lleven a cabo la tareas de identificar, relacionar y presentar la información. Precisamente una de las razones de la propuesta es superar las limitaciones que se encuentran los motores de búsqueda al procesar documentos con información textual poco estructurada y sin descripción normalizada.
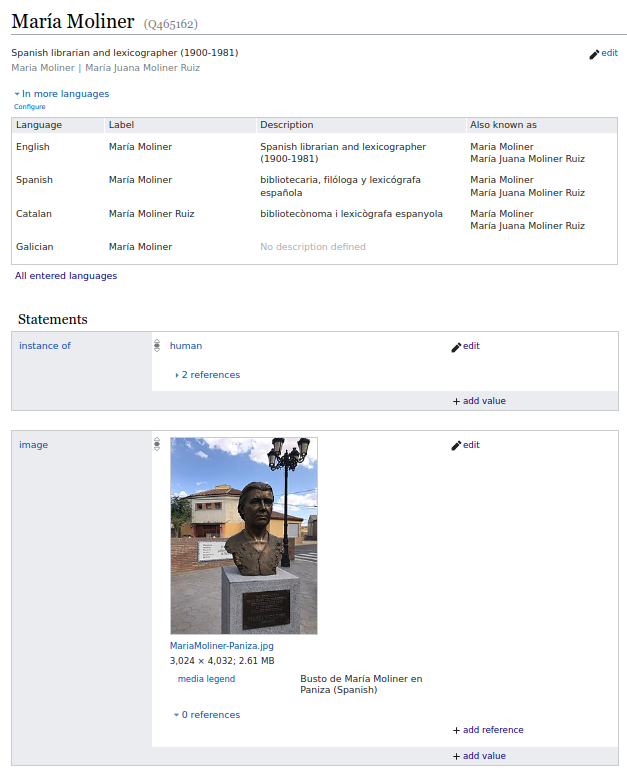 Fig. 3. María Moliner etiquetada semánticamente en Wikidata (fuente original).
Fig. 3. María Moliner etiquetada semánticamente en Wikidata (fuente original).
Los proyectos de web semántico se están centrado en etiquetar y hacer interoperables grandes silos de datos etiquetados, como los catálogos, y en la creación de ontologías, como recursos de descripción de entidades. A través de estas técnicas es posible relacionar informaciones de manera automática, integrándola desde diferentes recursos, y eliminado las posibles inconsistencias o confusiones entre las entidades. Sin embargo, y en lo que concierne a la búsqueda de información en internet, su uso aún no se ha hecho común, y los motores sólo hacen un aprovechamiento limitado, principalmente de los etiquetados de metadatos.