1.2 Tipos de aprendizaje o cómo aprenden las máquinas
1.2 Tipos de aprendizaje
o cómo aprenden las máquinas



Aprender sin entender: una idea clave antes de empezar
Cuando hablamos de aprendizaje en Inteligencia Artificial conviene detenerse un momento y ajustar expectativas, especialmente en el ámbito educativo. Las máquinas no aprenden como aprendemos las personas. No sienten curiosidad, no tienen intención de mejorar ni conciencia de lo que hacen. Y, sin embargo, aprenden.
En IA, aprender significa algo muy concreto: ajustar un modelo matemático a partir de datos para que, con el tiempo, cometa menos errores en una tarea concreta. No hay comprensión del contenido, sino detección de regularidades numéricas. Donde una persona entiende un concepto, una máquina identifica patrones estadísticos. Esta diferencia es esencial para comprender tanto el potencial como los límites de la IA en educación.
El aprendizaje automático como núcleo de la IA moderna
El corazón de la Inteligencia Artificial actual es el aprendizaje automático o Machine Learning (ML). A diferencia de la programación clásica —en la que el ser humano escribe reglas explícitas—, en el aprendizaje automático no se le indica a la máquina cómo resolver el problema, sino que se le muestran ejemplos para que descubra por sí misma qué funciona mejor.
Un paralelismo muy útil para el profesorado es el siguiente: programar un sistema tradicional se parece a dar una receta paso a paso; entrenar un sistema de IA se parece más a poner muchos ejemplos corregidos y dejar que el sistema extraiga conclusiones. El resultado suele ser más flexible y potente, aunque también más difícil de explicar.
A partir de esta idea general, podemos distinguir varios tipos de aprendizaje, según cómo se presentan los datos y qué tipo de información recibe el sistema durante su entrenamiento.
Aprendizaje supervisado: aprender con corrección

El aprendizaje supervisado es el más intuitivo desde el punto de vista docente, porque se parece mucho a la enseñanza tradicional. El sistema aprende a partir de ejemplos que incluyen la respuesta correcta. Cada vez que se equivoca, recibe una señal de error que le permite ajustar su comportamiento.
Es, en esencia, aprender con ejercicios corregidos.
Se utiliza cuando sabemos claramente qué queremos que el sistema aprenda: clasificar, predecir o identificar algo concreto.
En educación, este tipo de aprendizaje está presente en sistemas que:
-
predicen resultados académicos,
-
detectan riesgo de abandono,
-
corrigen pruebas objetivas,
-
estiman el progreso del alumnado a partir de datos históricos.
Su principal fortaleza es la precisión. Su principal debilidad es la dependencia total de la calidad de los datos: si los ejemplos están sesgados o mal etiquetados, el sistema aprenderá mal.
Aprendizaje no supervisado: descubrir sin que nadie explique
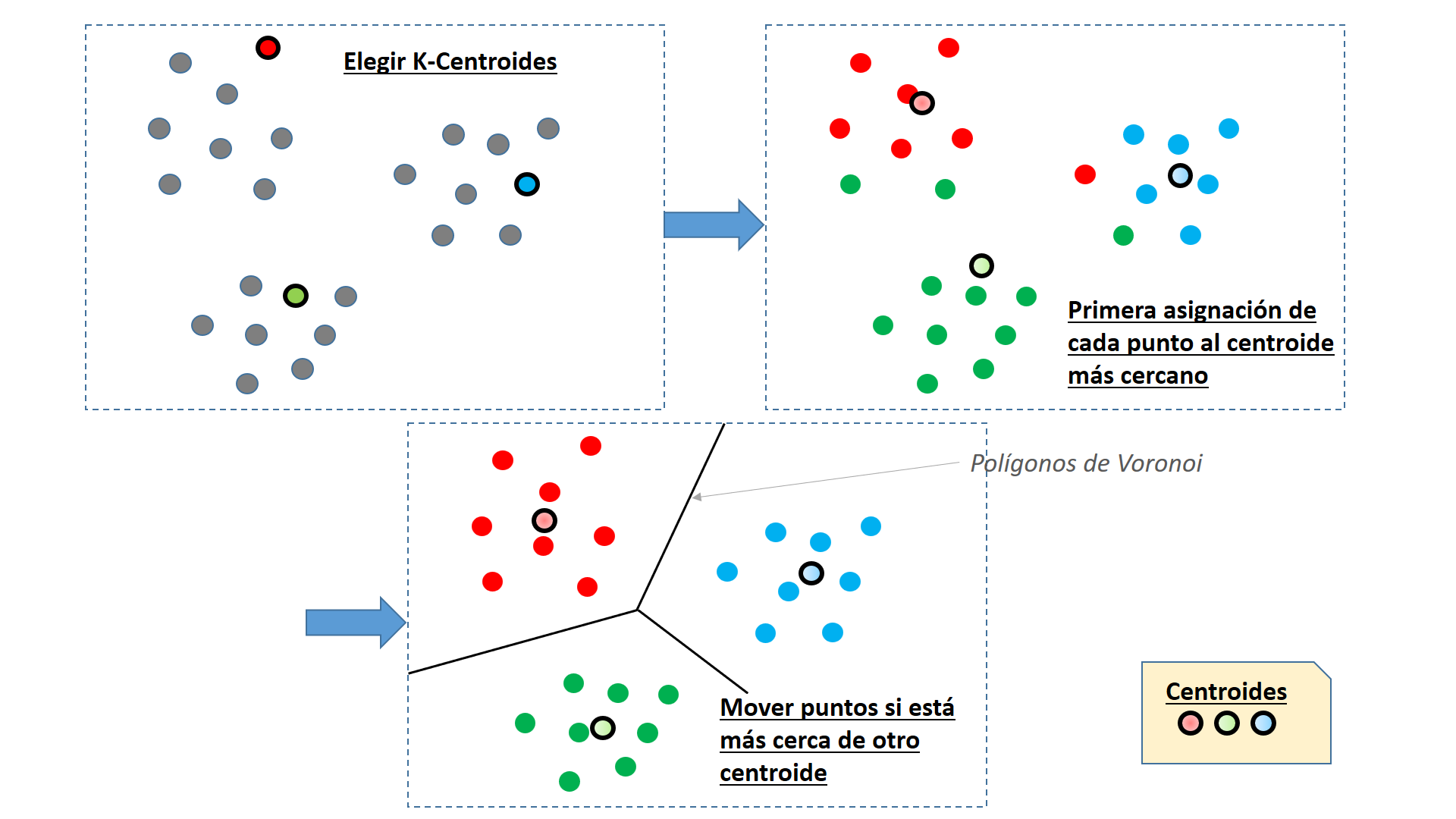
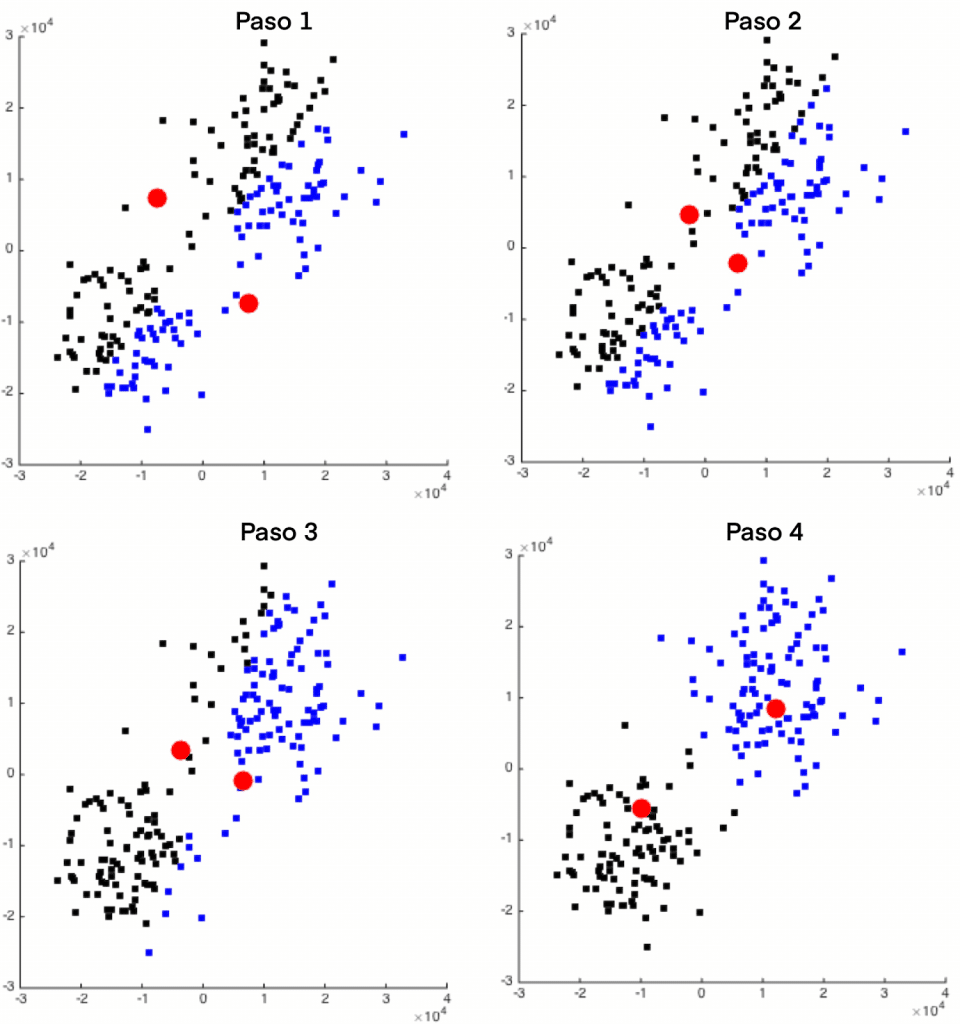
En el aprendizaje no supervisado, la máquina no recibe respuestas correctas. Simplemente analiza grandes volúmenes de datos y busca estructuras internas: similitudes, agrupaciones o patrones que se repiten.
Este tipo de aprendizaje resulta especialmente interesante en contextos educativos porque no sirve tanto para calificar como para comprender fenómenos complejos. Por ejemplo, permite detectar perfiles de alumnado con comportamientos similares, identificar patrones de uso de plataformas educativas o descubrir relaciones ocultas entre variables que no se habían considerado.
La máquina no “sabe” qué significan esos grupos. La interpretación pedagógica la pone siempre el ser humano. Por eso, el aprendizaje no supervisado no sustituye al profesorado, sino que le ofrece nuevas miradas sobre los datos.
Aprendizaje por refuerzo: aprender actuando

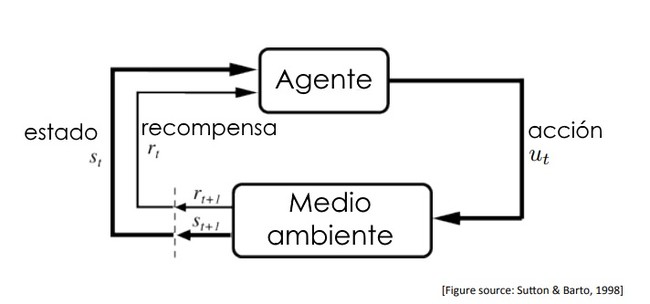

El aprendizaje por refuerzo se basa en una idea muy sencilla: aprender mediante ensayo y error. El sistema actúa en un entorno, recibe recompensas o penalizaciones y ajusta su comportamiento para maximizar la recompensa a largo plazo.
No hay ejemplos corregidos ni patrones predefinidos. Solo consecuencias.
El ejemplo más conocido es AlphaGo, desarrollado por DeepMind, que aprendió a jugar millones de partidas contra sí mismo. En este proceso no solo imitó a los humanos, sino que descubrió estrategias nuevas, demostrando que el aprendizaje por refuerzo puede generar comportamientos inesperados y muy eficaces.
En educación, este enfoque es especialmente interesante para:
-
simuladores,
-
entornos de práctica,
-
agentes educativos que aprenden cuándo intervenir y cuándo dejar explorar.
Aprendizaje profundo: cuando las redes neuronales escalan


El aprendizaje profundo o Deep Learning (DL) no es un tipo de aprendizaje distinto, sino una forma avanzada de implementar los anteriores mediante redes neuronales con muchas capas. Estas redes son capaces de aprender representaciones muy complejas de los datos, lo que ha permitido avances espectaculares en texto, imagen y audio.
Gracias al Deep Learning, la IA es capaz de:
-
reconocer rostros,
-
entender voz,
-
traducir idiomas,
-
generar texto, imágenes o música.
A cambio, estos modelos son grandes, opacos y difíciles de explicar. En educación, esto plantea un reto importante: sabemos que funcionan, pero no siempre sabemos por qué.
Aprendizaje en modelos de lenguaje y agentes
Los modelos de lenguaje de gran tamaño (LLMs) aprenden principalmente prediciendo la siguiente palabra o fragmento de palabra a partir de las anteriores. Todo el texto se convierte previamente en números, y el modelo aprende regularidades profundas del lenguaje a partir de enormes volúmenes de datos.
Sobre estos modelos se construyen los agentes de IA, que no solo generan texto, sino que:
-
toman decisiones,
-
usan herramientas,
-
consultan información externa,
-
encadenan acciones para alcanzar objetivos.
Aquí el aprendizaje ya no es solo lingüístico, sino también interactivo.
Aprender máquinas, aprender personas: el paralelismo educativo
Llegados a este punto, resulta inevitable comparar cómo aprenden las máquinas con cómo aprendemos las personas. Aunque los mecanismos sean distintos, los paralelismos son muy útiles desde el punto de vista pedagógico.
Gran parte del aprendizaje humano es supervisado: el alumnado aprende con explicaciones, ejemplos y correcciones del profesorado. El error, igual que en la IA, no es un fallo, sino una señal para mejorar.
También aprendemos de forma no supervisada. Descubrimos patrones, normas sociales o relaciones entre conceptos sin que nadie nos las explique directamente. Observamos, inferimos y construimos significado, del mismo modo que los algoritmos detectan estructuras en los datos.
Existe además un aprendizaje semisupervisado, muy habitual en educación: proyectos, investigaciones y situaciones de aprendizaje donde hay orientaciones iniciales, pero no soluciones cerradas. Este enfoque es cada vez más importante también en IA.
Y, por supuesto, aprendemos mediante refuerzo. Las consecuencias de nuestras acciones —éxito, fracaso, reconocimiento, frustración— influyen en cómo actuamos en el futuro. La diferencia es que, en las personas, estas recompensas están cargadas de significado emocional y social.
Las máquinas optimizan funciones matemáticas.
Las personas aprenden construyendo sentido.
1.3 Límites, sesgos y riesgos del aprendizaje automático
Comprender cómo aprenden las máquinas es imprescindible para usarlas bien, pero no es suficiente. Igual de importante es entender sus límites.
El primero es el sesgo. La IA aprende de datos humanos y, por tanto, hereda errores, prejuicios y desigualdades presentes en esos datos. Un sistema entrenado con información parcial o injusta reproducirá esas mismas distorsiones, a menudo de forma invisible.
El segundo límite es la opacidad. Muchos modelos, especialmente los basados en Deep Learning, funcionan como una “caja negra”: ofrecen resultados muy precisos, pero difíciles de explicar. En educación, esto obliga a extremar la prudencia cuando se utilizan para evaluar, clasificar o tomar decisiones relevantes.
El tercero es la apariencia de inteligencia. Los sistemas de IA pueden expresarse con seguridad incluso cuando se equivocan, lo que puede generar una falsa sensación de fiabilidad. Comprender que la IA no entiende, sino que predice, es clave para desarrollar pensamiento crítico en el alumnado.
Un cierre necesario para el aula
La Inteligencia Artificial aprende, pero no sabe lo que aprende.
Las personas aprendemos, pero además sabemos por qué y para qué.
Por eso, en educación, la IA debe entenderse como una herramienta poderosa de apoyo, análisis y personalización, nunca como un sustituto del criterio pedagógico.
Las máquinas aprenden con datos; las personas aprenden con sentido, valores y acompañamiento.