Unidad 2.3 Tipos de Machine Learning
CONTENIDOS
Introducción
El aprendizaje automático se basa en la búsqueda de patrones en ingentes cantidades de datos. Por ejemplo sirve para reconocer la diferencia entre gatos y perros. En lugar de decirle explícitamente qué buscar, le muestras un montón de fotos de gatos y perros que hacen que de algún modo aprenda la 'relación' entre ellos y así poder predecir el tipo de animal cuando vea una imagen nueva.
Dicho paradigma tiene tres vertientes o tipos:
-
Aprendizaje Supervisado: Es como si le mostrases fotos y le dijeses: “Esto es un gato” o “Esto es un perro”. El robot aprende de los ejemplos que le das para poder decir si la próxima foto que ve es un gato o un perro.
-
Aprendizaje No Supervisado: Es un poco diferente. Aquí, simplemente le das un montón de fotos sin decirle cuál es cuál. El robot tiene que ver las fotos y decir: “Hmm, estas fotos se parecen entre sí, y estas otras fotos se parecen entre sí, así que creo que hay dos grupos diferentes aquí”.
-
Aprendizaje por Refuerzo: Es como entrenar a un perro. Cada vez que el robot acierta (por ejemplo, dice correctamente si es un gato o un perro), le das una “golosina virtual” y cuando se equivoca, le dices “inténtalo de nuevo”. Así, el robot está motivado para mejorar y aprender correctamente.
El aprendizaje automático es básicamente enseñarle a una computadora a aprender de los ejemplos y la experiencia, en lugar de seguir instrucciones específicas como en la programación tradicional
Estos paradigmas difieren en las tareas que pueden resolver y en cómo se presenta los datos a la computadora. Por lo general, la tarea y los datos determinan directamente qué paradigma se debe utilizar (y en la mayoría de los casos, es el aprendizaje supervisado). Sin embargo, en algunos casos hay que tomar una decisión. A menudo, estos paradigmas se pueden utilizar juntos para obtener mejores resultados. Este capítulo ofrece una visión general de qué son estos paradigmas de aprendizaje y para qué se pueden utilizar.
Aprendizaje Supervisado
El aprendizaje supervisado es el paradigma de aprendizaje más común. En el aprendizaje supervisado, la computadora aprende a partir de un conjunto de pares de entrada-salida, que se llaman ejemplos etiquetados:
![]()
En este caso identificamos entradas (imágenes de perros y gatos, características de setas, datos del mercado de valores etc...) y salidas (tipo de animal, clase de seta, valor futuro de una acción).
El objetivo del aprendizaje supervisado suele ser entrenar un modelo predictivo a partir de estos pares. Un modelo predictivo es un programa que puede adivinar el valor de salida (también conocido como etiqueta) para una nueva entrada no vista. En pocas palabras, la computadora aprende a predecir utilizando ejemplos de predicciones correctas.
Por ejemplo, consideremos un conjunto de datos de características de animales (ten en cuenta que los conjuntos de datos típicos son mucho más grandes):
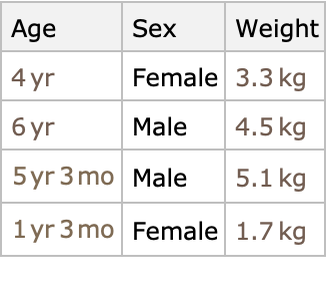
Nuestro objetivo es predecir el peso de un animal a partir de sus otras características, por lo que reescribimos este conjunto de datos como un conjunto de pares de entrada-salida:
Las variables de entrada (en este caso, edad y sexo) generalmente se denominan características, y el conjunto de características que representan un ejemplo se llama vector de características. A partir de este conjunto de datos, podemos generar un modelo que nos permita predecir pesos a partir de nuevos datos (edad y sexo) de entrada.
La regresión y la clasificación son las principales tareas del aprendizaje supervisado, pero este paradigma va más allá de estas tareas. Por ejemplo, la detección de objetos es una aplicación del aprendizaje supervisado en la que la salida consta de múltiples clases y sus posiciones de caja correspondientes, así el modelo se entrena usando imágenes y sus datos asociados incluyendo las posiciones en forma de rectángulo de cada objeto incluido en la imagen.
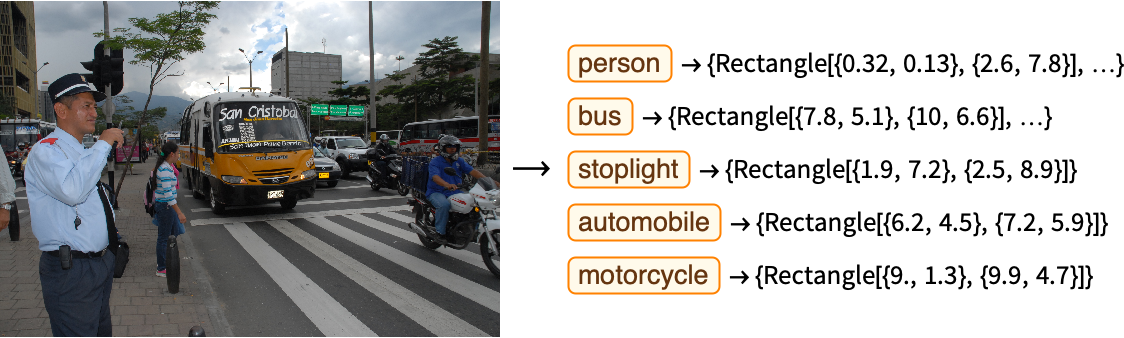
Otro ejemplo de este tipo de aprendizaje es la traducción de textos, en este caso entrada y salida son textos de cada lengua involucrada.
Podríamos imaginar todo tipo de otros tipos de salidas. Mientras los datos de entrenamiento consistan en un conjunto de pares de entrada-salida, es una tarea de aprendizaje supervisado.
Actualmente, la mayoría de las aplicaciones de aprendizaje automático que se desarrollan utilizan un enfoque de aprendizaje supervisado. Una razón para esto es que las principales tareas supervisadas (clasificación y regresión) son útiles y están bien definidas, y a menudo se pueden abordar utilizando algoritmos simples. Otra razón es que se han desarrollado muchas herramientas para este paradigma. Sin embargo, la principal desventaja del aprendizaje supervisado es que necesitamos tener datos etiquetados, lo cual puede ser difícil de obtener en algunos casos.
Aprendizaje No Supervisado
El aprendizaje no supervisado es el segundo paradigma de aprendizaje más utilizado. No se utiliza tanto como el aprendizaje supervisado, pero es más potente y se asemeja más al funcionamiento del cerebro humano. En el aprendizaje no supervisado, no hay entradas ni salidas, los datos son simplemente un conjunto de ejemplos caracterizados por ciertos datos que permiten su agrupación en conjuntos similares de entidades.
El aprendizaje no supervisado se puede utilizar para una amplia gama de tareas. Una de ellas se llama agrupamiento y su objetivo es separar los ejemplos de datos en grupos llamados clústeres:
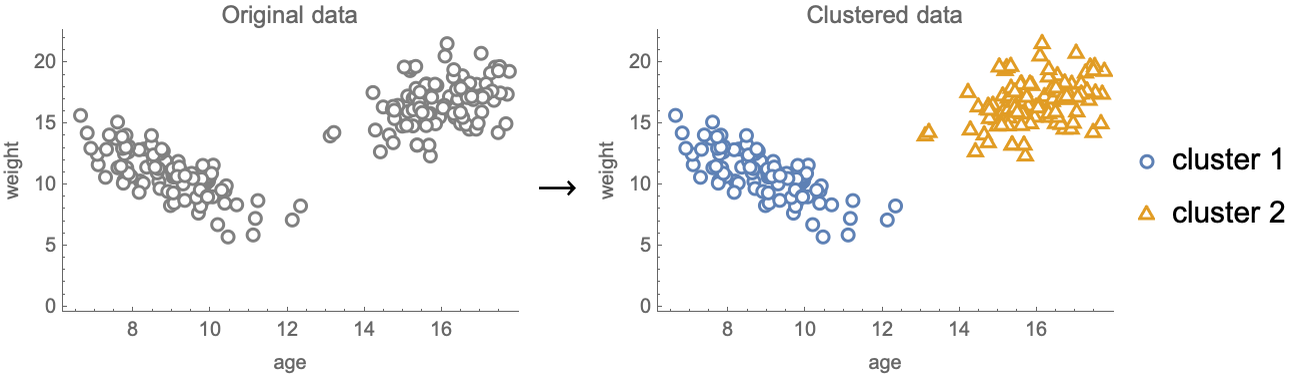
Una aplicación del agrupamiento podría ser separar automáticamente a los clientes de una empresa para crear mejores campañas de marketing. El agrupamiento también se utiliza simplemente como una herramienta de exploración para obtener información sobre los datos y tomar decisiones fundamentadas. También permite detectar casos extraños (outliers) que suelen asociarse a fraudes o errores al ser ejemplos que quedan fuera de cualquier grupo, por ejemplo en un conjunto de transacciones o patrones de comportamiento de clientes de banca.
Otra tarea clásica de aprendizaje no supervisado se denomina reducción de dimensionalidad. El objetivo de la reducción de dimensionalidad es reducir el número de variables en un conjunto de datos al tiempo que se intenta preservar algunas propiedades de los datos, como las distancias entre ejemplos. Muchos datos incluyen decenas de parámetros que los definen, por ejemplo
en una imagen cada pixel es un parámetro o dimensión, usar muchas imágenes con muchos pixeles complica demasiado y sobre todo ralentiza el algoritmo con lo que conviene reducir el número de pixeles eliminando los superfluos o que no aportan mucha información.
La reducción de dimensionalidad se puede utilizar para una variedad de tareas, como comprimir los datos, aprender con etiquetas faltantes, crear motores de búsqueda o incluso crear sistemas de recomendación. La reducción de dimensionalidad también se puede utilizar como una herramienta de exploración para visualizar un conjunto de datos completo en un espacio reducido (ver Capítulo 7).reducido.

La detección de anomalías (ver Capítulo 7, Reducción de Dimensionalidad, y Capítulo 8, Aprendizaje de Distribuciones) es otra tarea que se puede abordar de manera no supervisada. La detección de anomalías se refiere a la identificación de ejemplos que son anómalos, es decir, valores atípicos. Aquí tienesvemos un ejemplo de detección de anomalías realizada en un conjunto de datos numéricos simple:
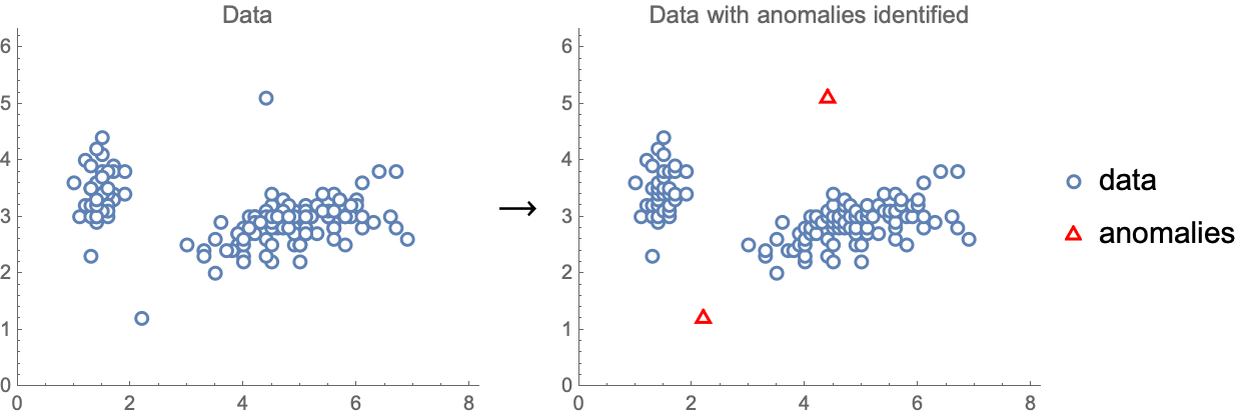
Esta tarea podría ser útil para detectar transacciones fraudulentas con tarjetas de crédito, limpiar un conjunto de datos o detectar cuando algo está saliendo mal en un proceso de fabricación.
Otra tarea clásica de aprendizaje no supervisado se denomina imputación de valores faltantes (ver Capítulo 7 y Capítulo 8),faltantes, y el objetivo es completar los valores faltantes en un conjunto de datos:
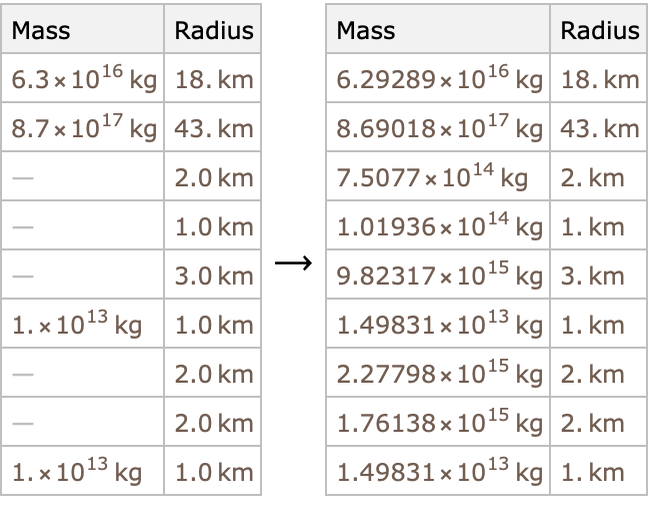
Esta tarea es extremadamente útil porque la mayoría de los conjuntos de datos tienen valores faltantes y muchos algoritmos no pueden manejarlos. En algunos casos, las técnicas de imputación de valores faltantes también se pueden utilizar para tareas predictivas, como los motores de recomendación (ver Capítulo 7).recomendación.
Finalmente, la tarea de aprendizaje no supervisado más difícil probablemente sea aprender a generar ejemplos similares a los datos de entrenamiento. Esta tarea se llama modelado generativo (ver Capítulo 8) y se puede utilizar, por ejemplo, para aprender a generar nuevos rostros a partir de muchos ejemplos de rostros. Aquí tienes algunos ejemplos de rostros sintéticos generados por una red neuronal a partir de ruido aleatorio:

Técnicas de generación como estas también se pueden utilizar para mejorar la resolución, reducir el ruido o completar valores faltantes.
El aprendizaje no supervisado se utiliza un poco menos que el aprendizaje supervisado, principalmente porque las tareas que resuelve son menos comunes y más difíciles de implementar que las tareas predictivas. Sin embargo, el aprendizaje no supervisadoembargo se puede aplicar a un conjunto más diverso de tareas que el aprendizaje supervisado. En la actualidad, el aprendizaje no supervisado es un elemento clave en muchas aplicaciones de aprendizaje automático y también se utiliza como una herramienta para explorar datos. Además, muchos investigadores creen que el aprendizaje no supervisado es la forma en que los humanos adquieren la mayor parte de sus conocimientos y, por lo tanto, será la clave para desarrollar sistemas artificialmente inteligentes en el futuro.
Aprendizaje de refuerzo
El tercer paradigma de aprendizaje clásico se llama aprendizaje por refuerzo, que es una forma en que los agentes autónomos aprenden. El aprendizaje por refuerzo es fundamentalmente diferente del aprendizaje supervisado y no supervisado en el sentido de que los datos no se proporcionan como un conjunto fijo de ejemplos. En cambio, los datos para aprender se obtienen interactuando con un sistema externo llamado entorno. El nombre "aprendizaje por refuerzo" proviene de la psicología del comportamiento, pero también podría llamarse "aprendizaje interactivo".
El aprendizaje por refuerzo se utiliza a menudo para enseñar a los agentes, como robots, a aprender una tarea determinada. El agente aprende tomando acciones en el entorno y recibiendo observaciones de este entorno:
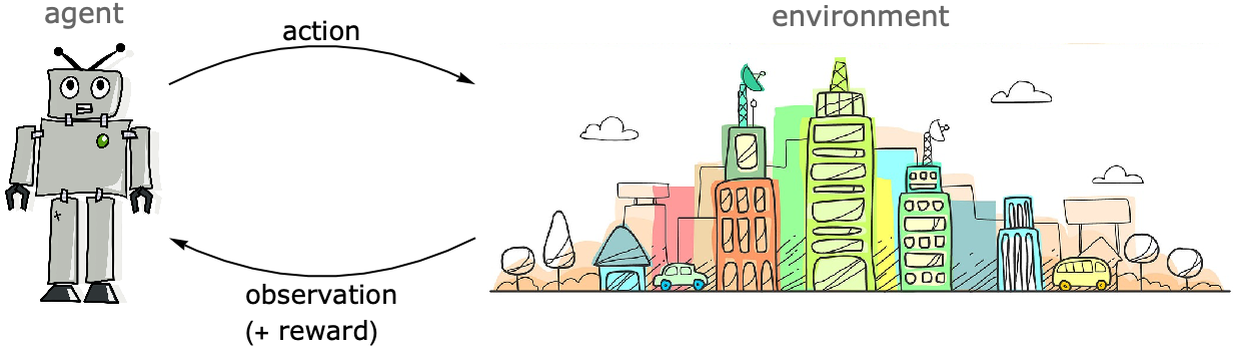
Normalmente, el agente comienza su proceso de aprendizaje actuando al azar en el entorno, y luego el agente aprende gradualmente de su experiencia para realizar mejor la tarea utilizando una especie de estrategia de prueba y error. El aprendizaje generalmente está guiado por una recompensa que se le da al agente según su desempeño. Más precisamente, el agente aprende una política que maximiza esta recompensa. Una política es un modelo que predice qué acción tomar dados los anteriores acciones y observaciones.
El aprendizaje por refuerzo se puede utilizar, por ejemplo, para que un robot aprenda a caminar en un entorno simulado. Aquí hay una captura de pantalla del clásico entorno Ant-v2:


También es posible que un robot real aprenda sin un entorno simulado, pero los robots reales son más lentos en comparación con los simulados y los algoritmos actuales tienen dificultades para aprender lo suficientemente rápido. Una estrategia de mitigación consiste en aprender a simular el entorno real, un campo conocido como aprendizaje por refuerzo basado en modelos, que está siendo objeto de investigación activa.
El aprendizaje por refuerzo también se puede utilizar para enseñar a las computadoras a jugar juegos. Ejemplos famosos incluyen AlphaGo,AlphaGo, que puede vencer a cualquier jugador humano en el juego de mesa Go,Go, o AlphaStar,AlphaStar, que puede hacer lo mismo en el videojuego StarCraft:StarCraft:
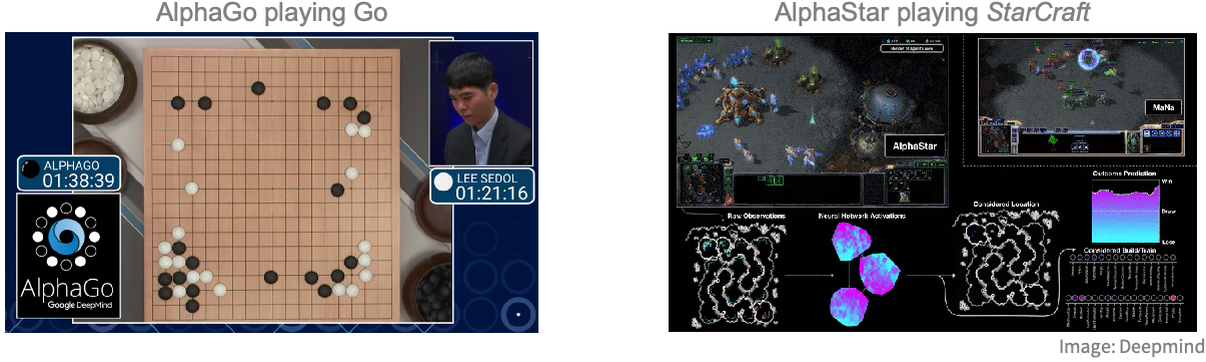
Ambos programas fueron desarrollados utilizando aprendizaje por refuerzo al hacer que el agente juegue contra sí mismo. Cabe destacar que la recompensa en este tipo de problemas solo se otorga al final del juego (ya sea que ganes o pierdas), lo que dificulta aprender qué acciones fueron responsables del resultado.
Otra aplicación importante del aprendizaje por refuerzo se encuentra en el campo de la ingeniería de control. El objetivo aquí es controlar de manera dinámica el comportamiento de un sistema (un motor, un edificio, etc.) para que se comporte de manera óptima. El ejemplo prototípico es controlar un poste que se encuentra sobre un carrito moviendo el carrito hacia la izquierda o hacia la derecha (también conocido como péndulo invertido):
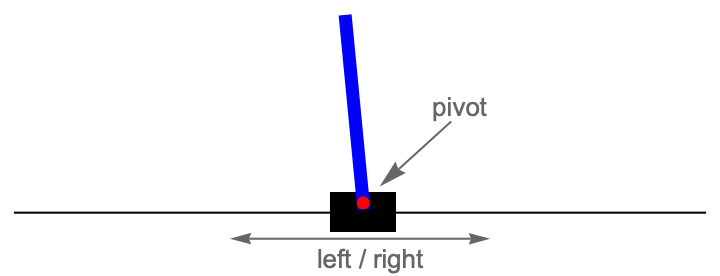
En general, se utilizan métodos de control clásicos para este tipo de problemas, pero el aprendizaje por refuerzo está entrando en este campo. Por ejemplo, se ha utilizado el aprendizaje por refuerzo para controlar el sistema de enfriamiento (velocidad del ventilador, flujo de agua, etc.) de los centros de datos de Google de manera más eficiente:
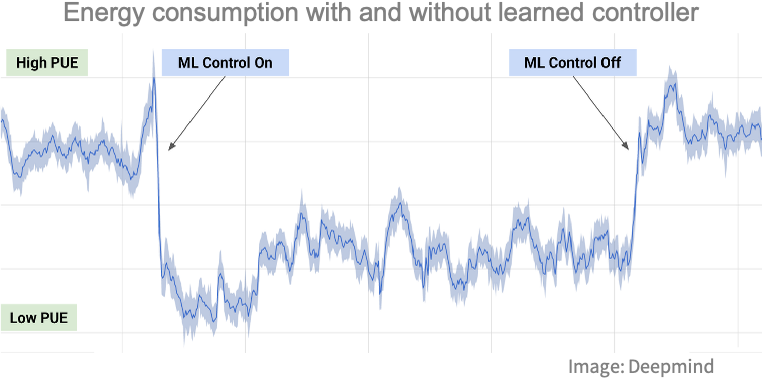
Un problema al aplicar el aprendizaje por refuerzo directamente en un sistema del mundo real es que durante la fase de aprendizaje, el agente podría realizar acciones que podrían dañar el sistema o plantear problemas de seguridad.
El aprendizaje por refuerzo es probablemente el paradigma más emocionante, ya que el agente aprende interactuando, como un ser vivo. Los sistemas activos tienen el potencial de aprender mejor que los sistemas pasivos porque pueden decidir por sí mismos qué explorar para mejorar. Podemos imaginar todo tipo de aplicaciones utilizando este paradigma, desde un robot agrícola que aprende a mejorar la producción de cultivos, hasta un programa que aprende a operar en el mercado de valores, o un chatbot que aprende teniendo conversaciones con humanos. Desafortunadamente, los algoritmos actuales requieren una gran cantidad de datos para ser efectivos, por lo que la mayoría de las aplicaciones de aprendizaje por refuerzo utilizan entornos virtuales. Además, los problemas de aprendizaje por refuerzo son generalmente más complicados de manejar que los problemas supervisados y no supervisados. Por estas razones, el aprendizaje por refuerzo se utiliza menos que otros paradigmas en aplicaciones prácticas. A medida que la investigación avanza, es probable que los algoritmos necesiten menos datos para operar y se desarrollen herramientas más simples. El aprendizaje por refuerzo podría convertirse en un paradigma dominante en el futuro.
REFERENCIAS
Video:
Video demostrativo (1min 40 segundos) del aprendizaje por refuerzo
Libro: Machine Learning For Dummies
https://www.ibm.com/downloads/cas/GB8ZMQZ3
RefFuenteWeb: https://www.wolfram.com/language/introduction-machine-learning/machine-learning-paradigms/
ACTIVIDADES
Actividad A2.3.1
Título: Tipos de aprendizaje
Objeto: Reflexionar sobre ejemplos concretos para entender los tipos de aprendizaje
Descripción: Identifica si cada caso de uso es un ejemplo de aprendizaje supervisado (S), de refuerzo (R) o no supervisado (NS). Escribe la letra correspondiente al lado de cada caso.
- Clasificar correos electrónicos como "spam" o "no spam".
- Agrupar clientes en diferentes segmentos según sus patrones de compra.
- Predecir el precio de una casa basándose en características como el tamaño, la ubicación y el número de habitaciones.
- Enseñar a un software a jugar y mejorar en videojuegos como Pac-Man o Super Mario
- Identificar patrones comunes en datos de series temporales de ventas.
- Clasificar imágenes de radiografías para detectar si hay una fractura.
- Agrupar noticias relacionadas en categorías basadas en su contenido.
- Entrenar a un dron para que aterrice de manera segura en diferentes condiciones
- Predecir si un paciente tiene una enfermedad específica basándose en sus síntomas.
- Identificar grupos de productos similares en un catálogo de comercio electrónico.
- Determinar la categoría de un artículo de blog (por ejemplo, tecnología, salud, deportes).
Materiales: -
Entrega:
Documento pdf que incluya las respuestas razonadas a los supuestos planteados
El nombre del fichero es: apellido1_nombre_a231.pdf
Actividad A2.3.2
Título: Tipos de aprendizaje
Objeto: Reflexionar sobre los posibles usos de Machine Learning en el ámbito educativo
Descripción: Supón que dispones de todos los datos posibles de alumnos de un centro, incluyendo notas de asignaturas, perfil académico, currículum, situación familiar.
Piensa de que forma podría aprovecharse dicha información (o una parte de la misma) para obtener conclusiones acerca del alumnado
(Siempre tomando en cuenta que los datos son anonimizados y en ningún caso se contemplan datos identificatorios)
Materiales: -
Entrega:
Documento pdf que incluya las reflexiones y conclusiones debidamente justificadas
El nombre del fichero es: apellido1_nombre_a232.pdf