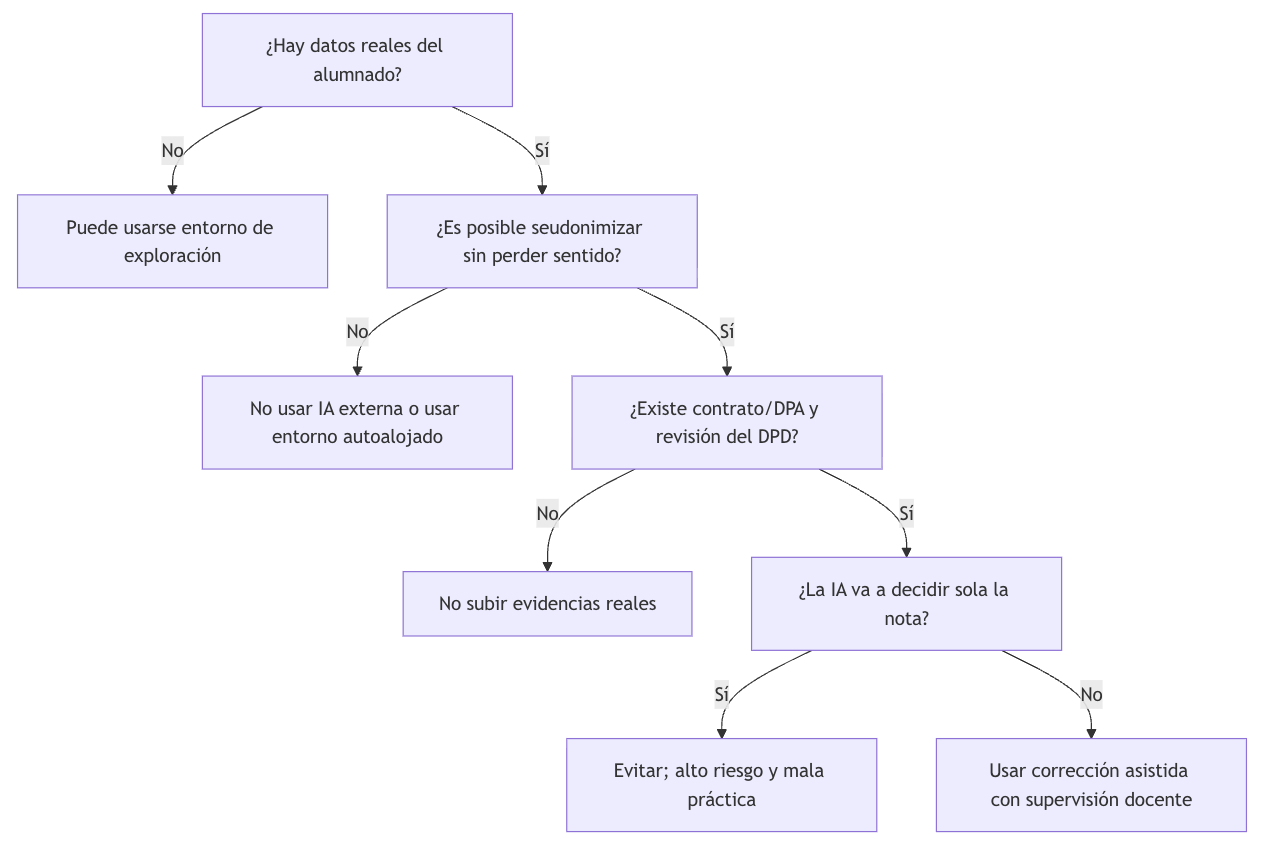
4.3. Estrategias para trabajar con textos y evidencias sin datos identificativos
La anonimización es una estrategia básica para poder usar IA con cierto nivel de seguridad. No consiste solo en borrar el nombre, sino en eliminar o sustituir toda información que permita identificar a una persona directa o indirectamente, es decir, reducir la reidentificación por contexto, contenido o metadatos.
En educación, esto implica revisar no solo el encabezado, sino también el contenido, los metadatos y cualquier pista contextual.
En evaluación, una estrategia sencilla es separar identidad y evidencia mediante códigos, y trabajar únicamente con el texto o el producto que se va a analizar.
Flujo seguro recomendado:
-
Recoger la evidencia.
-
Sustituir nombres por códigos.
-
Eliminar datos del documento.
-
Revisar que no haya pistas evidentes de identidad.
-
Introducir solo el fragmento necesario en la IA.
-
Verificar la respuesta generada.
-
Archivar la versión original en entorno institucional seguro.
Ejemplo práctico:
Documento original: “María Pérez, 4.º ESO B”.
Versión para IA: “Alumno 07, 4.º ESO”.
Fragmento enviado: solo el texto de la redacción o el apartado relevante.
A veces basta con cambiar un nombre por un código, pero otras veces es necesario eliminar referencias a profesores, lugares, proyectos o circunstancias familiares que podrían hacer reconocible al alumno. Cuanto más sensible sea la información, más estricta debe ser la revisión.
Herramientas y niveles de madurez
La decisión no debe hacerse por “marca”, sino por madurez de gobernanza. La siguiente tabla resume el uso más prudente en centros.
| Nivel | Herramientas tipo | Uso recomendable | Condición de datos | Requisitos contractuales y riesgos |
| Exploración básica | ChatGPT personal, Claude consumer, Gemini Apps | Ideación de actividades, borradores de rúbricas, ejemplos ficticios | Sin datos reales del alumnado | En Gemini Apps, una parte de los chats puede revisarse por humanos y utilizarse para mejorar servicios; ciertos datos revisados pueden conservarse hasta 3 años. En servicios individuales de OpenAI, los datos de versiones para individuos pueden usarse para entrenamiento. En Claude consumer, inputs/outputs pueden usarse para entrenar salvo opt-out. |
| Entorno institucional gestionado | ChatGPT Business/Edu/API | Creación de instrumentos, revisión de textos seudonimizados, feedback asistido | Datos minimizados y seudonimizados | OpenAI indica que por defecto no entrena con datos de Business, Enterprise, Edu ni API; ofrece DPA, controles de retención y, en API, casos con zero data retention. |
| Suite corporativa integrada | Microsoft 365 Copilot | Comentado de documentos, resúmenes y borradores en ecosistema M365 | Solo con permisos bien gobernados | Microsoft indica que prompts, respuestas y datos de Graph no se usan para entrenar LLM fundacionales; funciona dentro del perímetro M365. Riesgo principal: permisos mal configurados. Además, algunos modelos Anthropic en experiencias Copilot quedan fuera del EU Data Boundary. |
| Plataforma cloud avanzada | Vertex AI / Google Cloud | Pipelines con JSON, RAG institucional, despliegues controlados | Datos institucionales bajo diseño técnico y jurídico | Google afirma que no usará datos para entrenar o afinar modelos sin permiso previo; aun así, puede haber logging para abuso y ciertos servicios de grounding almacenan prompts y salidas 30 días. |
| Servicios comerciales B2B | Anthropic Commercial / API | Corrección asistida o feedback si el centro contrata servicio empresarial | Datos minimizados y contrato | Anthropic establece en términos comerciales que el cliente conserva inputs y outputs y que Anthropic no puede entrenar modelos con Customer Content; además incorpora DPA. En consumo, la política es distinta. |
| Autoalojada / local | Gemma 4 + Ollama u otra infraestructura propia | Mayor soberanía, pruebas con datos internos, prototipos avanzados | Puede admitir datos reales si la arquitectura lo justifica y el centro controla todo el entorno | Gemma 4 se publica bajo licencia Apache 2.0, con soporte para JSON estructurado y despliegue on-prem; Google la presenta como apta para control total de datos e infraestructura. Ollama permite ejecución local sencilla e integración vía CLI/API. Riesgos: seguridad del servidor, evaluación del modelo, coste de mantenimiento. |
Sobre herramientas edtech específicas como MagicSchool, sí existe evidencia reciente de uso docente en generación de rúbricas, con buena percepción como borrador inicial y necesidad clara de edición humana.
¿Cómo decidir qué herramienta usar?
Aránzazu Cortés + Chat GPT